大模型蒸馏:从原理到争议全解析
大模型蒸馏:从原理到争议全解析
2025 年 1 月,DeepSeek-R1 横空出世,性能逼近 OpenAI o1,训练成本却低了一个数量级。此后围绕”蒸馏”的争议不断升级,2026 年 2 月 Anthropic 正式指控 DeepSeek 等中国公司通过大量虚假账户获取 Claude 的输出来训练模型。一时间,”蒸馏”这个词从技术圈的角落被推到了聚光灯下。
蒸馏到底是什么?它怎么运作?是创新还是剽窃?
一、蒸馏的起源:Hinton 的 “知识压缩”
2015 年,Geoffrey Hinton、Oriol Vinyals 和 Jeff Dean 发表了 Distilling the Knowledge in a Neural Network。核心想法很简单:一个能力强的模型(教师)的知识,可以被”蒸馏”到一个更小的模型(学生)里,就像把一大壶水浓缩成一小杯精华。当时的”教师”其实是多个模型的集成(ensemble),不是今天动辄千亿参数的大语言模型。
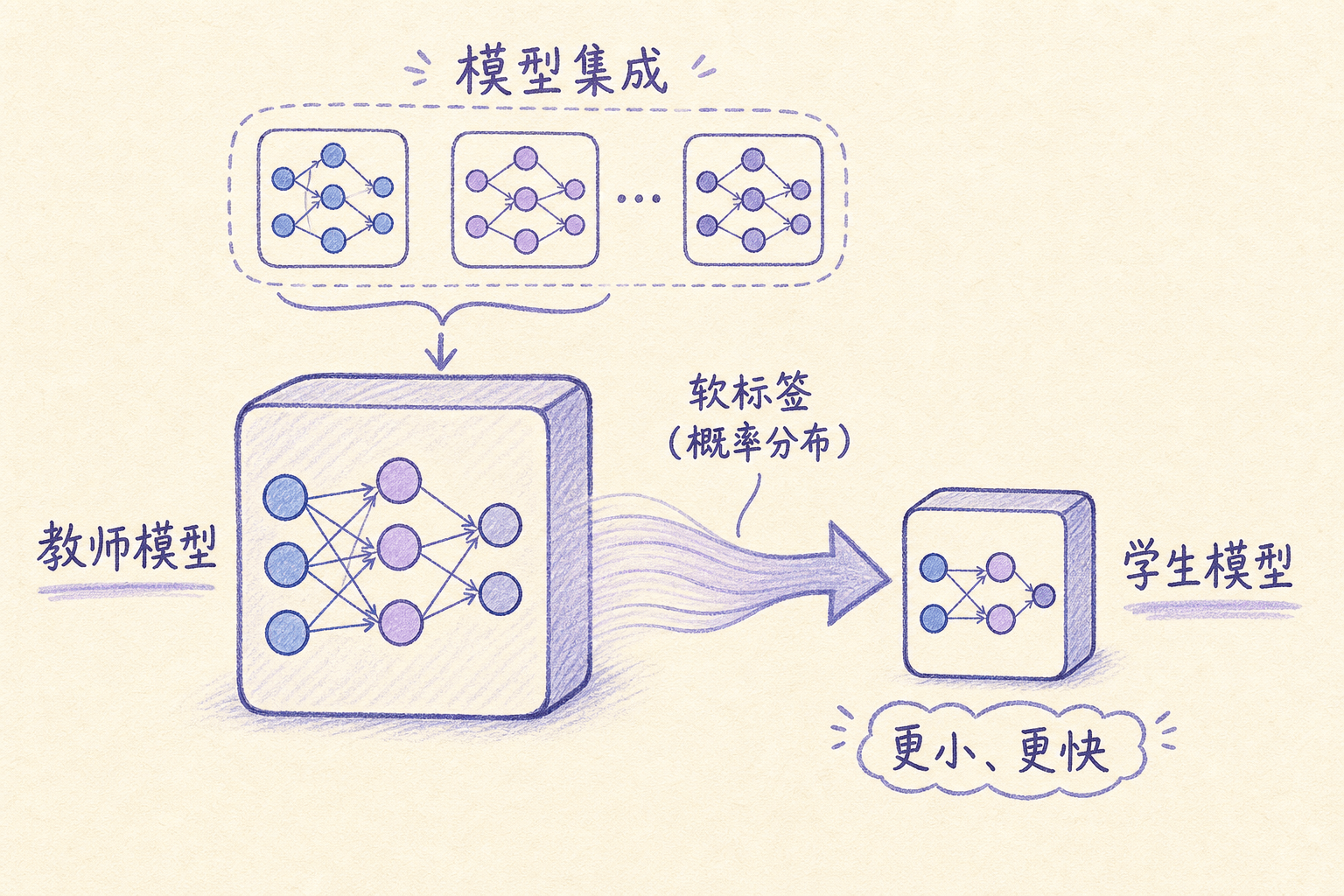
传统训练中,模型的输出是硬标签,比如图片分类任务,输出就是”猫”或”狗”。但 Hinton 注意到,教师模型的软输出(soft targets)蕴含着更丰富的信息。比如一张柴犬的照片,教师模型可能给出:
- 狗:0.85
- 狼:0.10
- 猫:0.05
这个概率分布告诉学生模型:照片里的柴犬最可能是狗,但也有点像狼,和猫差得远。
温度参数:让概率分布更”柔软”
为了让软标签传递更多信息,Hinton 引入了温度参数 T。做法很简单:把模型的原始输出除以 T,再过 softmax。T 越大,概率分布越”平坦”,原本接近 0 的概率会被抬高,原本接近 1 的概率会被压低,不同类别之间的差异被抹平,暴露更多类间相似性信息。T=1 时就是标准 softmax。
$$q_i = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)}$$

训练过程
学生模型的训练损失由两部分组成:
- 软标签损失:学生模型的软输出与教师模型软输出之间的 KL 散度(乘以 $T^2$)
- 硬标签损失:学生模型输出与真实标签之间的交叉熵
总损失 = $\alpha \cdot T^2 \cdot KL(教师||学生) + (1-\alpha) \cdot CE(真实标签, 学生)$
通过这个组合损失,学生模型既学到了教师模型的”暗知识”(dark knowledge),也没偏离真实标签太远。
二、大模型时代的蒸馏:从图像分类到语言生成
Hinton 的蒸馏最初是为图像分类设计的。到了大模型时代,蒸馏的含义和方法都变了。
传统蒸馏 vs LLM 蒸馏
| 维度 | 传统蒸馏(2015) | LLM 蒸馏(2023-至今) |
|---|---|---|
| 模型规模 | 百万~亿参数 | 百亿~万亿参数 |
| 教师模型 | 单个或集成模型 | GPT-4、Claude 等商业模型 |
| 蒸馏对象 | 输出概率分布 | 输出文本、推理过程、思维链 |
| 训练方式 | 同时访问教师和学生权重 | 往往只能通过 API 访问教师 |
| 目标 | 压缩模型以降低推理成本 | 让小模型获得大模型的能力 |
白盒蒸馏 vs 黑盒蒸馏
LLM 蒸馏分为两种范式:
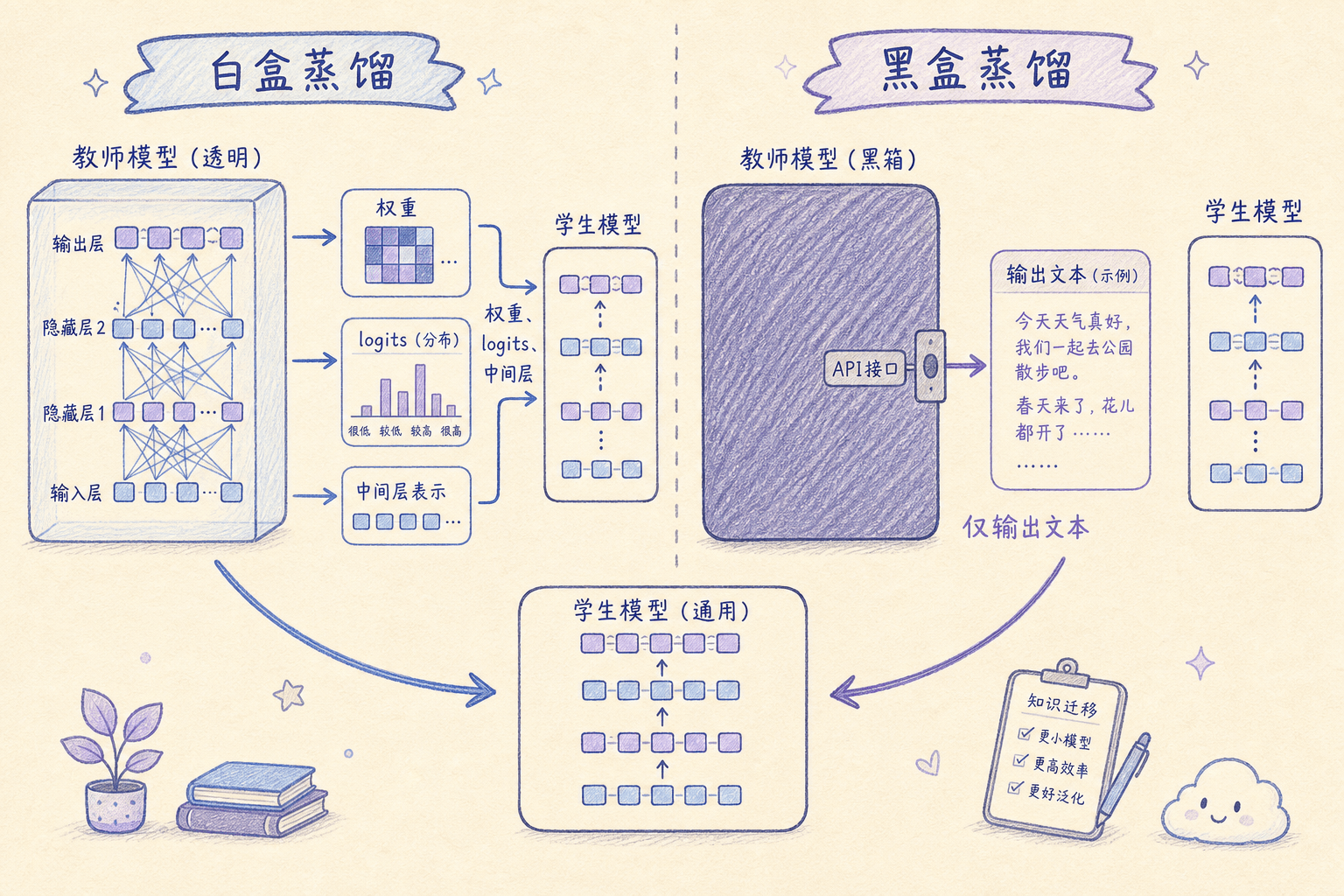
白盒蒸馏(White-box Distillation),教师模型的权重和内部状态完全可访问。学生模型可以直接学习教师模型的 logits 分布、中间层表示等。这种方法信息量最大,但要求教师模型是开源的或者你自己拥有。
MiniLLM(ICLR 2024)就是白盒蒸馏的代表工作。它用反向 KL 散度(reverse KLD)替代传统的正向 KL 散度,解决了生成式语言模型蒸馏中的一个关键问题:正向 KL 散度会让学生模型在教师模型概率低的区域过度分配概率,导致生成质量下降。反向 KL 散度则鼓励学生模型”保守”,只在自己有把握的地方分配概率。
黑盒蒸馏(Black-box Distillation),教师模型只能通过 API 访问,看不到内部权重和概率分布。学生模型通过模仿教师模型的输出文本来学习。这是当前最常见、也最具争议的方式。
黑盒蒸馏的典型流程:
- 用一组 prompt 调用教师模型的 API,获取输出
- 将 (prompt, 输出) 对作为训练数据
- 用这些数据对学生模型进行监督微调(SFT)
这种方法简单直接,但很有效。Alpaca、Vicuna、WizardLM 等早期开源模型,都是通过黑盒蒸馏 ChatGPT 的输出训练出来的。
思维链蒸馏(Chain-of-Thought Distillation)
传统的蒸馏只传递”答案”,思维链蒸馏还传递”推理过程”。教师模型在回答问题时,不仅给出最终答案,还展示完整的推理步骤。学生模型学的不只是结论,而是整个思维过程,这让小模型也能展现出接近大模型的推理能力。
三、DeepSeek-R1 的蒸馏实践
DeepSeek-R1 是蒸馏技术在大模型时代最引人注目的实践。
DeepSeek-R1 的训练流程
DeepSeek-R1 本身是通过大规模强化学习(RL)训练出来的,在数学、编程、科学等领域展现出了很强的推理能力,能自我反思、验证和动态调整策略。但 DeepSeek-R1 体量很大,推理成本高。为了让这种推理能力惠及更多场景,DeepSeek 团队做了两件事:
- 蒸馏到更小的模型:将 DeepSeek-R1 的推理能力蒸馏到基于 Qwen2.5 和 LLaMA-3 系列的小模型上,参数规模从 1.5B 到 70B 不等
- 开源所有蒸馏模型:6 个蒸馏模型全部以 MIT 协议开源
蒸馏方法
DeepSeek 的蒸馏方法很直接:
- DeepSeek-R1 生成了约 80 万条包含完整推理链的样本(带有
<think>标签的思维过程) - 用这些样本对基座模型(Qwen2.5、LLaMA-3)进行监督微调(SFT)
- 蒸馏过程中没有额外的强化学习
结果出乎意料:仅通过 SFT 蒸馏的小模型,在很多基准测试上就超过了用 RL 训练的同等规模模型。DeepSeek-R1-Distill-Qwen-32B 在多个基准上达到了与 OpenAI o1-mini 相当的水平。
为什么蒸馏比 RL 训练更有效?
一个合理的解释:强化学习需要模型自己”探索”正确的推理路径,效率低。蒸馏直接把教师模型已经发现的推理路径”告诉”了学生模型。不过这也引出一个问题:蒸馏出来的能力是”真正的理解”还是”模式模仿”?至今没有定论。
四、蒸馏的争议
DeepSeek-R1 发布后,围绕蒸馏的争议逐步升级。2025 年 1 月,有报道称 OpenAI 和微软正在调查 DeepSeek 是否通过 API 蒸馏了他们的模型。2026 年 2 月,Anthropic 正式指控 DeepSeek 及其他中国公司”使用数千个虚假账户与 Claude 进行数百万次对话”来训练自己的模型。
各方立场
Anthropic 的指控最为具体,指向的是通过大量 API 调用获取模型输出用于训练的行为。OpenAI 的服务条款同样明确禁止用户使用其模型输出来训练竞争模型。
DeepSeek 方面否认不当使用了其他公司的模型。DeepSeek-R1 的技术报告说明,该模型是通过纯强化学习训练的,蒸馏只是后续将能力迁移到小模型的步骤。技术报告详细描述了训练流程,包括使用自家的 DeepSeek-V3 作为基座模型、大规模 RL 训练、以及使用 80 万条自生成数据进行蒸馏。从报告来看,训练流程是自洽的。
争议的核心
争议的核心不在于 DeepSeek 是否使用了蒸馏技术(所有 AI 公司都在用),而在于几点:
- 蒸馏的来源:从自己的开源模型蒸馏是完全合法的,但从别人的商业模型蒸馏就涉及服务条款问题
- 证据问题:如何证明一个模型的输出是”蒸馏”自另一个模型?模型的输出本身不包含来源信息
- 公平性问题:如果一家公司花了数亿美元训练模型,另一家公司通过 API 调用就能获得类似的能力,这公平吗?
- 技术可行性:即使确实从其他模型的输出中学习了一部分知识,这在整体训练流程中占多大比重?
行业反响
这个争议在 AI 行业引发了广泛讨论:
- 支持模型厂商的观点:蒸馏商业模型违反了服务条款,本质上是搭便车行为,会打击原始创新者的积极性
- 支持 DeepSeek 的观点:蒸馏是合法的技术手段,服务条款不应该限制技术进步;而且 DeepSeek 的核心创新(RL 训练框架)是独立的
- 中间立场:蒸馏本身无可厚非,关键是要区分合法的知识学习和违规的服务条款违反
五、蒸馏是好是坏?
蒸馏作为技术手段本身是中性的,好坏取决于怎么用、从哪蒸馏、用来做什么。
蒸馏的积极面
降低 AI 的门槛,蒸馏让小团队和研究机构也能获得接近大模型的能力。没有蒸馏,只有少数科技巨头才能训练和部署有能力的 AI 模型。
推动技术民主化,DeepSeek 的蒸馏模型以 MIT 协议开源,任何人都可以免费使用,加速了整个领域的进步。
提高效率,大模型已经证明某种能力可行的情况下,蒸馏比从头训练更高效。
促进创新,蒸馏让更多人能站在巨人的肩膀上,把精力集中在新的创新上,而不是重复已经完成的工作。
蒸馏的问题
知识产权争议,蒸馏可能涉及知识产权和服务条款的问题。商业模型的输出是否应该被用于训练竞争模型,目前是悬而未决的法律和伦理问题。
能力天花板,蒸馏的学生模型很难超越教师模型。学生学到的是教师的输出模式,不是底层的理解能力,有时候只是在”模仿”而非”理解”。
质量控制,黑盒蒸馏的质量高度依赖教师模型的输出质量。教师模型的输出有偏见或错误,这些缺陷会被传递给学生模型。
安全风险,蒸馏过程没有适当的安全过滤,教师模型的有害行为模式也可能被传递给学生模型。
一个更平衡的视角
蒸馏不该被简单视为”抄袭”或”作弊”。学术界里,知识的传播和再利用是常态,论文被发表出来就是为了让别人引用、复现、改进。蒸馏可以被视为这种知识传播在 AI 领域的延伸。
不过,蒸馏也不该成为规避创新投入的捷径。一家公司的核心竞争力完全建立在蒸馏另一家公司的模型之上,而没有自己的技术积累,这种商业模式不可持续。
六、蒸馏的未来
蒸馏技术仍在快速发展,几个方向值得关注。
蒸馏 + 强化学习,DeepSeek 的实验表明,蒸馏和 RL 可以互补。先蒸馏获得基础能力,再用 RL 进一步提升,可能是更高效的训练路径。
自蒸馏(Self-Distillation),模型蒸馏自己,用自己生成的高质量数据来改进自己。这种方法避免了外部依赖,也不存在知识产权问题。
多教师蒸馏,从多个教师模型蒸馏,取各家之长,让学生模型获得更全面的能力。
蒸馏的可解释性,理解蒸馏到底传递了什么,是表面的模式还是深层的推理能力?这个问题的答案将决定蒸馏技术的上限。
总结
蒸馏是大模型时代最实用的技术之一,让小模型获得了大模型的能力,降低了 AI 的使用门槛。围绕 DeepSeek 的争议,本质上反映的是 AI 行业如何平衡创新激励与知识共享的问题。
对开发者来说,理解蒸馏的技术原理和边界,比纠结于争议本身更重要。蒸馏能传递模式,但不一定能传递理解。
参考文献
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531
- Gu, Y., et al. (2024). MiniLLM: Knowledge Distillation of Large Language Models. ICLR 2024. arXiv:2306.08543
- DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. Nature, 645, 633-638. arXiv:2501.12948