AI Agent 的反思机制:从原理到工程实践
Agent 不只是能行动,还能审视自己的行动。这种”元认知”能力,正是 Reflection 机制的核心。
在 Andrew Ng 归纳的 AI Agent 四大设计模式(Reflection、Tool Use、Planning、Multi-Agent)中,Reflection(反思) 是最接近人类学习方式的一种:做完一道题,回头检查哪里错了,下次避免。值得一提的是,这些设计模式并非凭空而来——在此之前,Yao 等人提出的 ReAct(Reasoning + Acting)框架已经奠定了 Agent “边想边做”的基础范式,其 Thought → Action → Observation 的交替循环被广泛融入了上述各模式的实现中。这个看似简单的机制效果惊人:据 Andrew Ng 披露,GPT-3.5 在 HumanEval 编程基准上从零样本 48.1% 飙升到 Agent 循环的 95.1%;而 Reflexion 论文本身报告了 91% pass@1 的成绩。
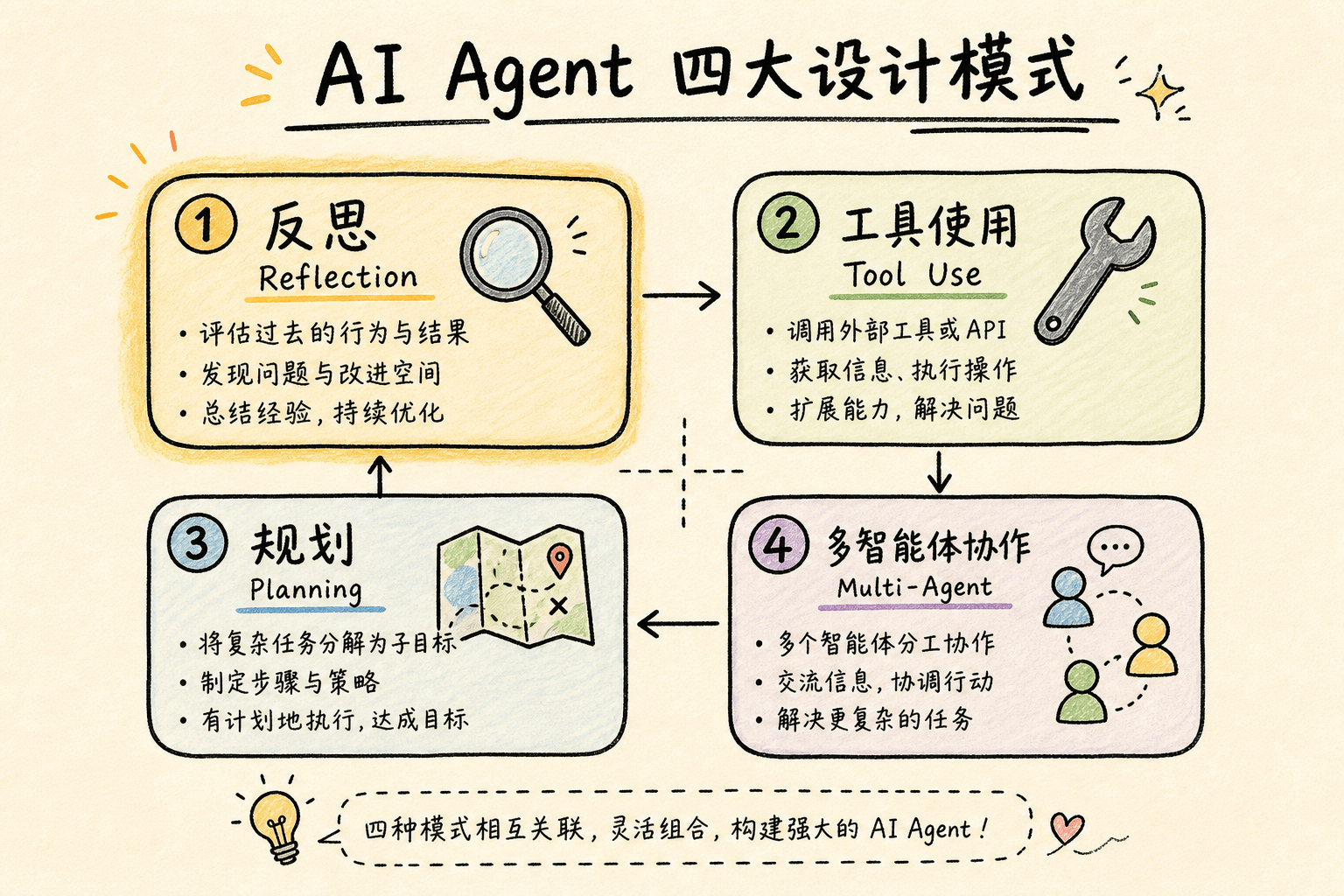
本文系统梳理 Reflection 机制的核心原理、主要变体、认知科学基础,以及工程实践中的关键限制。
什么是 Reflection?
Reflection 是 AI Agent 中一种自我改进机制:Agent 在完成任务后,对自己的输出、行为或推理过程进行审视和批评,从中提取经验教训,然后在下一次尝试中避免同样的错误。
类比人类学习:
- 做完一道数学题
- 对答案发现错了
- 回顾哪一步算错了
- 下次遇到类似题目时避免
这就是 Reflection 的核心思想。它不是一个单一的算法,而是一个设计范式(Design Pattern),有多种实现方式。
核心架构:Reflexion 论文
2023 年,Shinn 等人在 NeurIPS 上发表了 Reflexion: Language Agents with Verbal Reinforcement Learning(《Reflexion:基于语言反馈强化学习的语言智能体》),首次将 Reflection 形式化为一个由四个组件组成的迭代框架。这篇论文是该领域最核心的参考文献。
四个核心组件
Actor(行动者):基于 LLM 生成文本和执行动作,接受状态观察和记忆作为输入。类比学生做题。
Evaluator(评估者):对 Actor 的输出打分,可以是精确匹配、启发式规则、或 LLM 自评。类比老师批改。
Self-Reflection(自省):将稀疏的反馈信号(如对/错)转化为自然语言的反思文本,分析错误原因。类比学生写错题本。
Memory(记忆):存储反思文本作为长期记忆,在后续尝试中作为上下文提供给 Actor。类比错题本或经验库。
工作流程
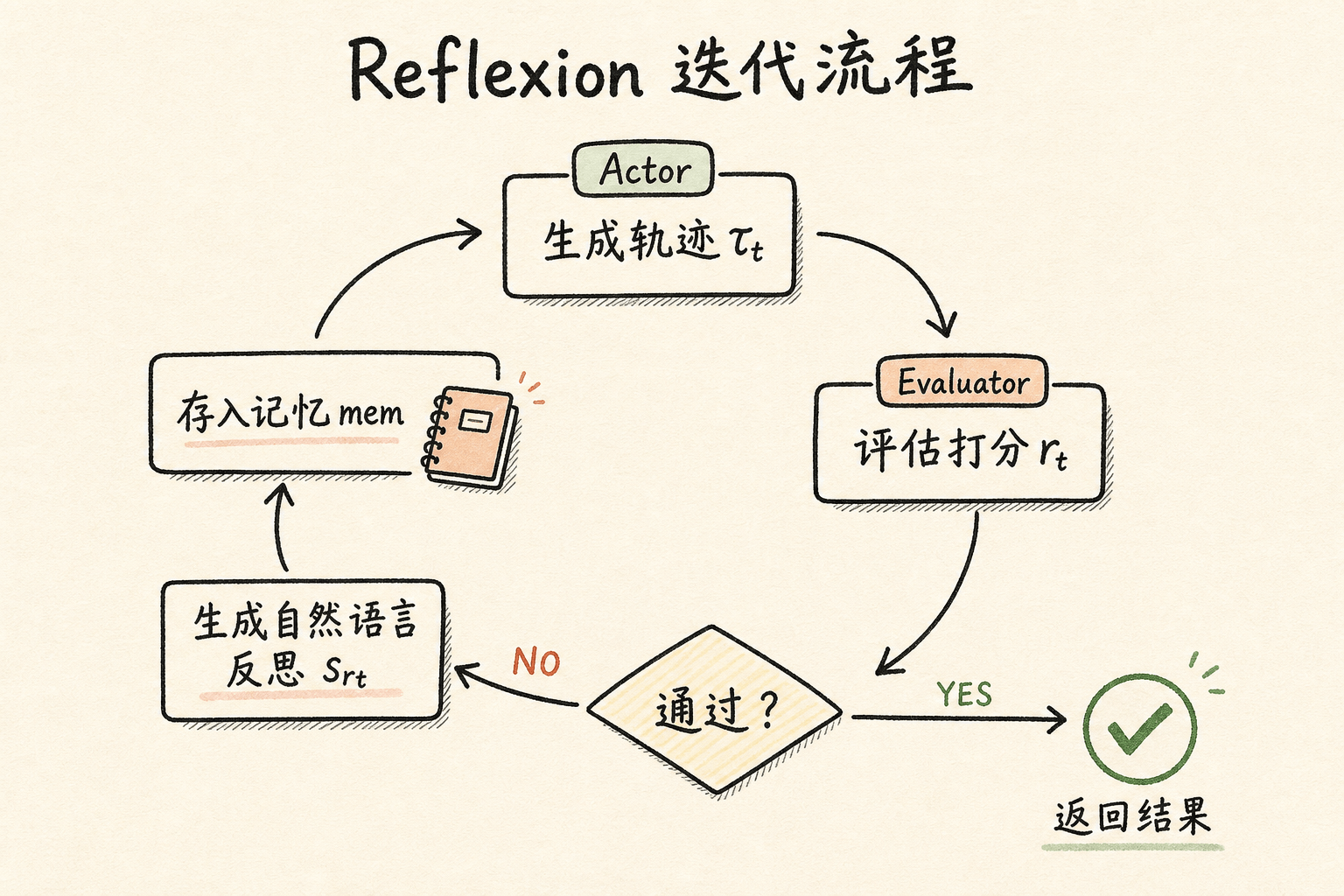
核心流程如下:
- Actor 基于当前策略和记忆 mem 生成轨迹 τt
- 评估者对 τt 打分,得到奖励 rt
- 自省模型分析 {τt, rt},生成自然语言反思 srt
- 将 srt 追加到记忆 mem
- 如果评估通过或达到最大试验次数,停止;否则回到步骤 1
关键创新点
语言化强化学习(Verbal Reinforcement Learning):不通过梯度下降更新权重,而是通过自然语言反思来”强化”Agent 的行为。这比传统 RL 轻量得多,不需要微调 LLM。
将标量奖励放大为语义反馈:传统 RL 只有一个数字奖励(比如 +1 或 -1),Reflexion 将”失败”这个信号转化为”你在哪里错了、应该怎么改”的详细语言描述。
情景记忆(Episodic Memory):反思文本存储在记忆中,后续尝试时 Agent 可以”回忆”过去的失败经验。实际实现中通常限制记忆大小为 1-3 条最近的反思,以适应上下文窗口限制。
实验结果
Reflexion 在三个不同领域取得了显著提升:
- ALFWorld(多步决策):ReAct 基线上 +22%,134 个任务完成 130 个
- HotPotQA(知识推理):CoT 基线上 +20%
- HumanEval(Python 编程):达到 91% pass@1,超过了当时 GPT-4 的 80%
值得注意的是,Reflexion 的学习曲线呈现典型的”快速提升 + 缓慢收敛”模式:前 2 次试验提升最明显,之后逐步逼近上限。
Reflection 的不同实现变体
Reflexion 开创了这个方向,但后续研究提出了多种不同的实现路径。
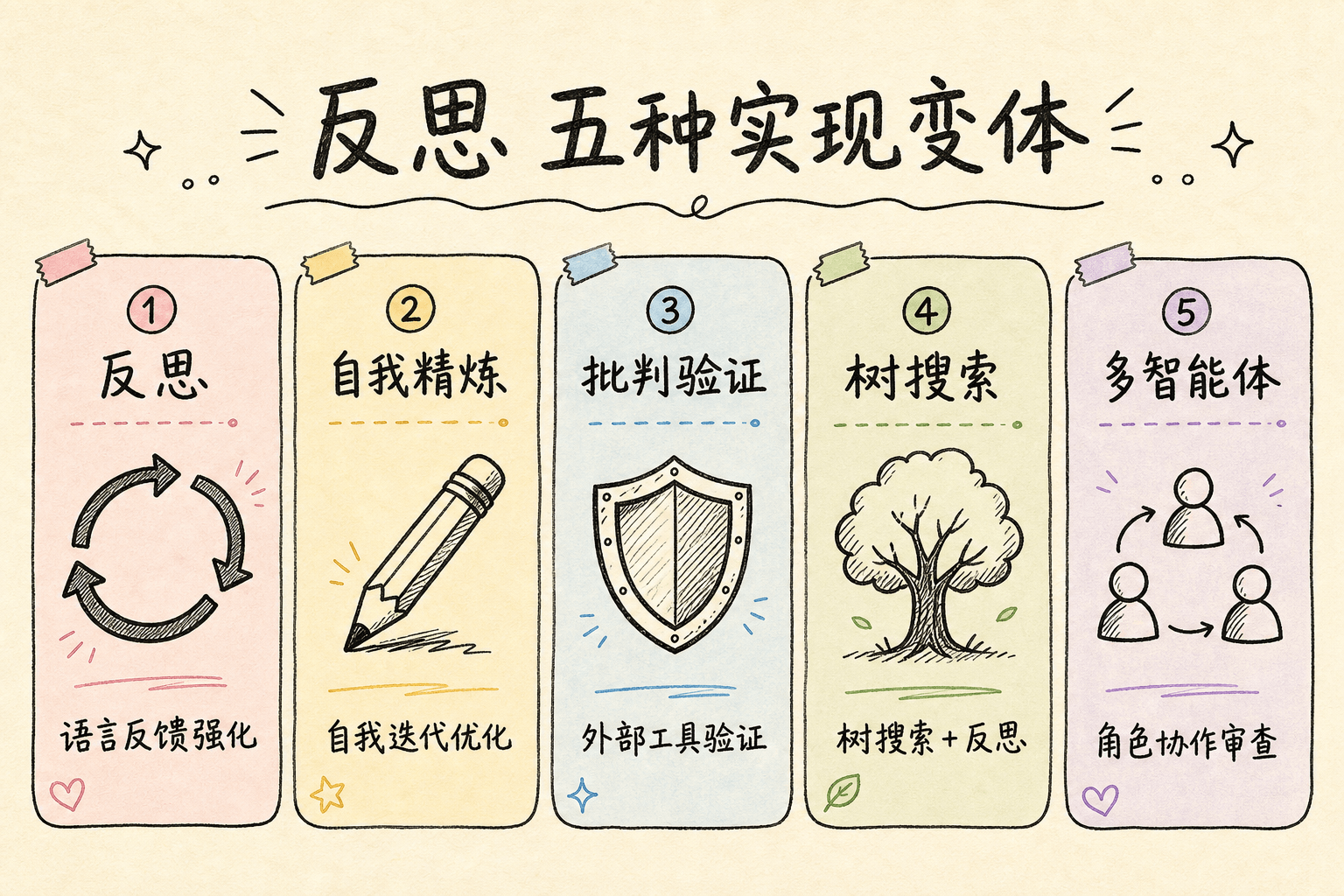
Self-Refine:单模型迭代优化
Madaan 等人在 2023 年提出 Self-Refine(Self-Refine: Iterative Refinement with Self-Feedback,即《Self-Refine:基于自我反馈的迭代优化》),核心思想是同一个 LLM 同时扮演三个角色——生成者、反馈提供者、优化者。
1 | |
Self-Refine 的特点是轻量,无需外部训练数据或工具,在 7 个任务上平均提升约 20%。但它限于单次生成的迭代优化,不像 Reflexion 可以跨试次学习。
CRITIC:引入外部工具验证
Gou 等人(ICLR 2024)提出 CRITIC(CRITIC: Large Language Models Can Self-Correct with Tool-Integrated Critique,即《CRITIC:大语言模型可通过工具集成批评实现自我纠错》),核心创新是使用外部工具(代码执行器、知识库检索等)来验证和修正 LLM 的输出,而不是纯靠 LLM 自我评估。
这个思路直接回应了一个关键问题——LLM 的自我评估能力到底可不可靠?CRITIC 的答案是:不可靠,需要外部工具来”把关”。
LATS:结合树搜索
Zhou 等人(2023)在 Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models(《语言智能体树搜索:统一语言模型中的推理、行动与规划》)中将蒙特卡洛树搜索(MCTS) 与 LLM 的自省能力结合,用 LLM 作为价值函数和反思模块来指导搜索。在 HumanEval 上用 GPT-4 达到 92.7% pass@1。
多 Agent 反思
在多 Agent 系统中,反思不是单个 Agent 自己做的,而是通过角色分工实现:
- ChatDev(清华/OpenBMB):模拟软件公司,CEO、CTO、程序员、测试员等角色互相审查代码和设计
- MetaGPT:用标准化流程(SOP)让不同角色验证中间结果,减少错误级联
这种”互相审查”的模式本质上是把单 Agent 的 Reflection 扩展到了多 Agent 协作场景。
Generative Agents:经验综合
Park 等人(2023)在 Generative Agents: Interactive Simulacra of Human Behavior(《生成式智能体:人类行为的交互式模拟》)中提出了 Observation → Reflection → Planning 三层架构。Reflection 层将具体的经验综合提炼为更高层次的洞察。
例如:Agent 观察到”今天阳光很好”、”我去了公园”、”我感觉很开心” → Reflection 层提炼出”我喜欢在好天气去户外活动”。这不再是简单的”纠错”,而是从经验中提取抽象知识。
认知科学基础
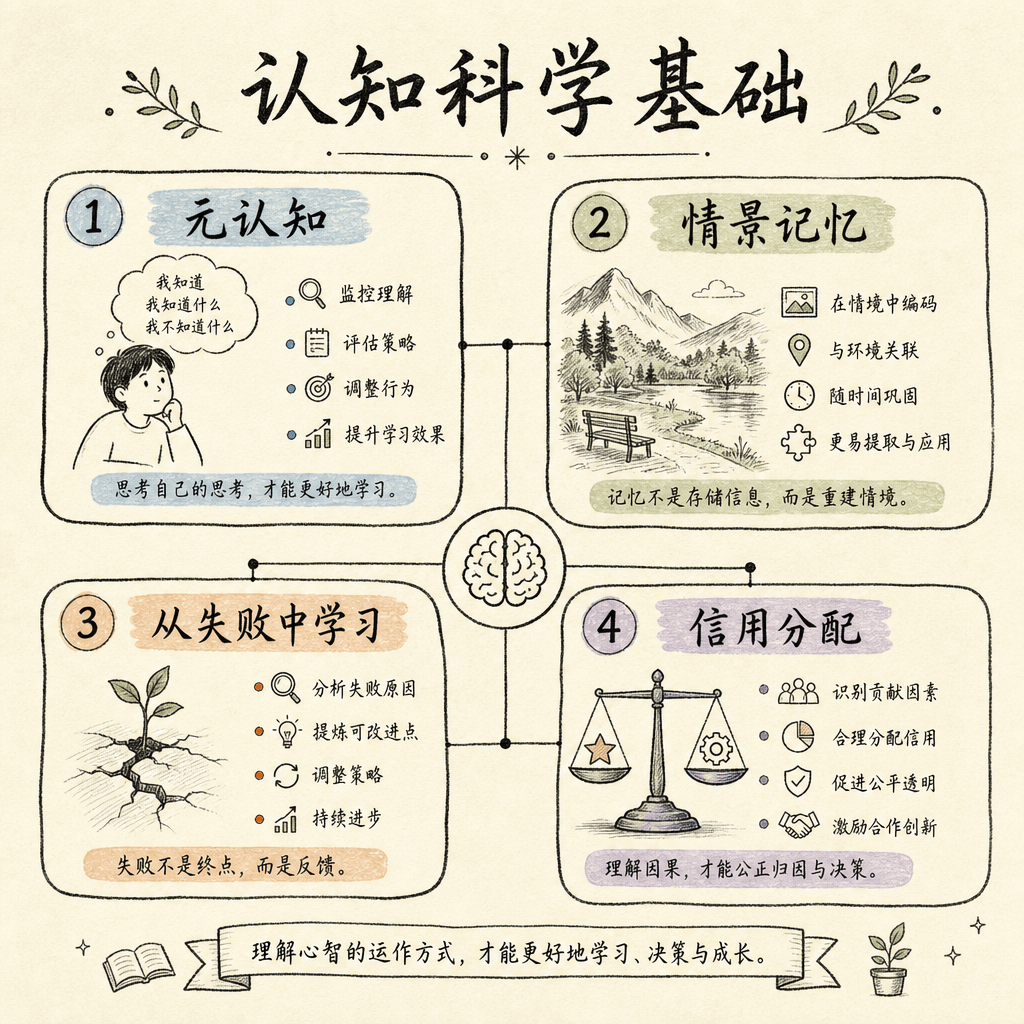
Reflection 的设计灵感来自人类认知中的几个关键机制:
元认知(Metacognition):对自己思维过程的思考。人类不只是做题,还会思考”我为什么做错了”、”我的解题策略哪里有问题”。
情景记忆(Episodic Memory):人类记得具体发生过的事情(”上次我在这里犯了这个错”),而不仅仅是抽象知识(”这个知识点是 X”)。Reflexion 的记忆系统正是模拟这一点。
从失败中学习(Learning from Failure):人类通过反思失败比单纯重复成功学得更快。Reflexion 的核心就是将失败信号转化为可操作的语言反馈。
信用分配(Credit Assignment):在多步任务中,人类能追溯”是第 3 步的选择导致了后面的失败”。Self-Reflection 模型正是做这件事——分析轨迹中哪一步出了问题。
关键限制:LLM 真的能”自我反思”吗?
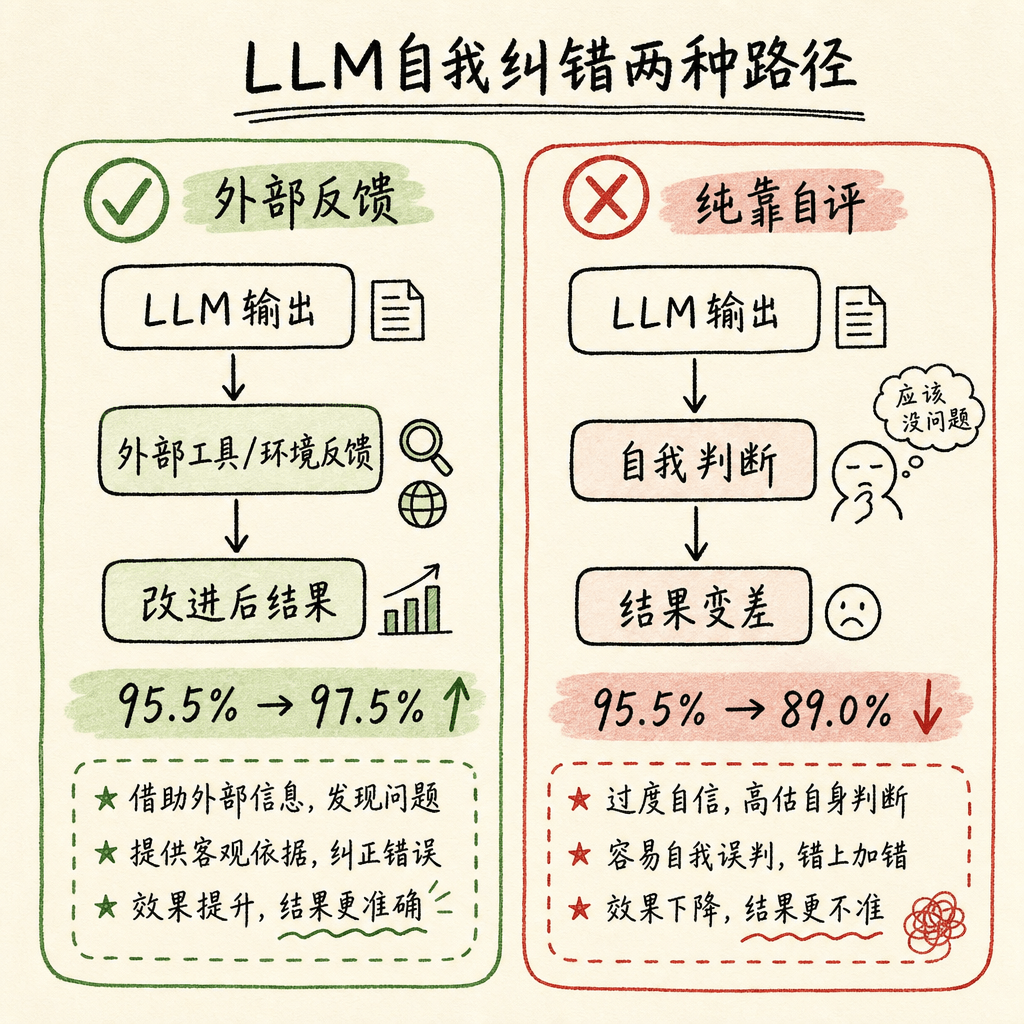
2023 年底,Huang 等人在 ICLR 2024 上发表了一篇重要的反面论文:Large Language Models Cannot Self-Correct Reasoning Yet(《大语言模型尚无法自我纠正推理》)。
核心发现
这篇论文区分了两种自我纠错场景:
有外部反馈的自我纠错:使用测试用例、正确答案标签等外部信号来指导纠错过程。结果:有效。
纯靠 LLM 自身判断的自我纠错(Intrinsic Self-Correction):要求 LLM 自己判断答案是否正确并修正。结果:性能反而下降。
具体数据:
| 场景 | GPT-4 准确率 |
|---|---|
| GSM8K 标准提示 | 95.5% |
| GSM8K 自我纠错(第 1 轮) | 91.5% |
| GSM8K 自我纠错(第 2 轮) | 89.0% |
GPT-3.5 在 CommonSenseQA 上更惨:从 75.8% 暴跌到 38.1%。
这意味着什么?
Reflexion 之所以有效,不是因为 LLM 真的能”自我反思”,而是因为它使用了外部反馈(环境反馈、测试用例、精确匹配等)作为反思的基础。纯靠 LLM 自己的判断来反思是不可靠的。
这个发现对工程实践有重要指导意义:设计 Reflection 机制时,必须引入外部验证手段(代码执行、测试用例、工具调用等),而不能指望 LLM 自己发现错误。
其他已知限制
- 依赖 LLM 能力上限:Reflection 只能帮助 LLM 接近自己的能力上限,不能突破
- 成本:每次反思都是一次额外的 LLM 调用,多次迭代会增加延迟和费用
- 记忆限制:受上下文窗口限制,只能存储有限条反思(通常 1-3 条)
- 反思质量不稳定:如果反思模型本身能力不足,生成的反思可能是错误的或无用的
工程实践:LangGraph 中的 Reflection
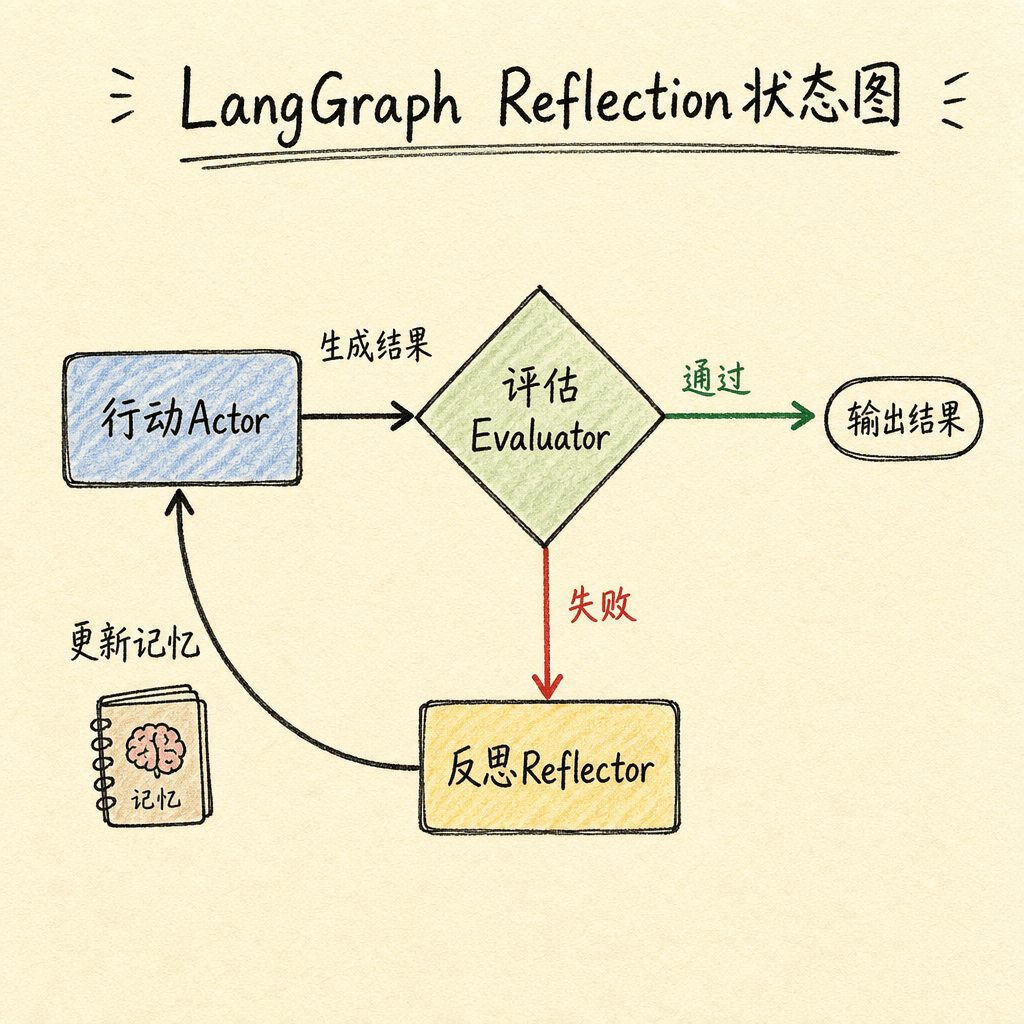
LangGraph 将 Reflexion 实现为一个状态图(StateGraph),包含三个节点:Actor(行动)、Evaluator(评估)、Reflector(反思),通过条件边连接。评估通过则输出结果,评估失败则反思后重新行动。这种图结构让 Reflection 的实现变得清晰可控,也便于调试和扩展。
在 LangGraph 的实现中,每个节点都是一个 LLM 调用,边代表状态转移条件。开发者可以灵活替换任何一个节点的模型,也可以在反思节点加入外部工具调用(如代码执行、知识库检索),从而实现 CRITIC 等变体。
总结
Reflection 是 AI Agent 从”能行动”到”能学习”的关键跨越。它的核心洞察是:将稀疏的反馈信号转化为语言化的经验教训,存储在记忆中供后续使用。
但实践中有几个关键原则:
- 必须有外部反馈:纯靠 LLM 自评不可靠,需要测试用例、环境信号、工具验证等外部机制
- 记忆是关键:没有跨试次的记忆积累,每次反思都是孤立的
- 反思质量决定上限:反思模型需要能准确定位错误原因,否则反思无用甚至有害
- 成本与效果的权衡:更多轮次的反思意味着更高成本,需要根据任务复杂度设置合理的迭代上限
随着 LLM 能力的持续提升,Reflection 机制的效果只会越来越好——因为更强的模型意味着更准确的反思和更有效的学习。
参考文献
- Shinn, N., Cassano, F., Berman, E., et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning(《Reflexion:基于语言反馈强化学习的语言智能体》). NeurIPS 2023. arXiv:2303.11366
- Madaan, A., et al. (2023). Self-Refine: Iterative Refinement with Self-Feedback(《Self-Refine:基于自我反馈的迭代优化》). ACL 2023. arXiv:2303.17651
- Huang, J., et al. (2023). Large Language Models Cannot Self-Correct Reasoning Yet(《大语言模型尚无法自我纠正推理》). ICLR 2024. arXiv:2310.01798
- Gou, Z., et al. (2023). CRITIC: Large Language Models Can Self-Correct with Tool-Integrated Critique(《CRITIC:大语言模型可通过工具集成批评实现自我纠错》). ICLR 2024. arXiv:2305.11738
- Zhou, A., et al. (2023). Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models(《语言智能体树搜索:统一语言模型中的推理、行动与规划》). arXiv:2310.04406
- Park, J. S., et al. (2023). Generative Agents: Interactive Simulacra of Human Behavior(《生成式智能体:人类行为的交互式模拟》). arXiv:2304.03442
- Andrew Ng. Agentic Design Patterns Part 2: Reflection(《Agentic 设计模式 Part 2:反思》). deeplearning.ai