为什么大语言模型能支持几乎所有人类语言?
一个在英文数据上训练出来的模型,凭什么能流畅地和你说中文、日语、阿拉伯语?本文从 Tokenization 到 Transformer 内部机制,拆解 LLM 多语言能力的底层原理。
一个反直觉的事实
大语言模型的训练数据高度偏向英语。CommonCrawl 等主流训练语料中,英文内容占比通常在 60-90% 之间,而剩下的数百种语言瓜分不到 40% 的份额。然而,这些模型不仅能处理中文、日语、阿拉伯语等与英语差异巨大的语言,甚至能回答关于低资源语言(如豪萨语、亚美尼亚语)的提问。
一个从英语数据中自回归学习下一个 token 的统计模型,为什么能泛化到几乎所有人类语言?
答案藏在模型处理语言的四个层面:Tokenization(分词)、Embedding(嵌入)、Transformer 层间计算、输出解码。每一层贡献了一块拼图。
一、Tokenization:语言进入模型的”海关”
任何文本进入 LLM 的第一步,是被切分成模型能处理的离散单元——token(分词单元)。这一步决定了模型会”看到”什么。
BPE:来自数据压缩的算法
BPE 原本是 Philip Gage 在 1994 年提出的数据压缩算法,2016 年被 Rico Sennrich 等人引入机器翻译领域,后来成为大语言模型的标配。
工作方式:
- 从一个字符级词表开始(所有单字符 + 特殊 token)
- 统计训练语料中相邻字符对的出现频率
- 将最频繁的字符对合并成一个新的子词
- 重复步骤 2-3,直到词表达到预设大小
举个例子,如果”th”和”e”频繁一起出现,BPE 就会把它们合并成”the”作为一个 token。同样,”un”+”believe”+”able”会被合并成”unbelievable”。
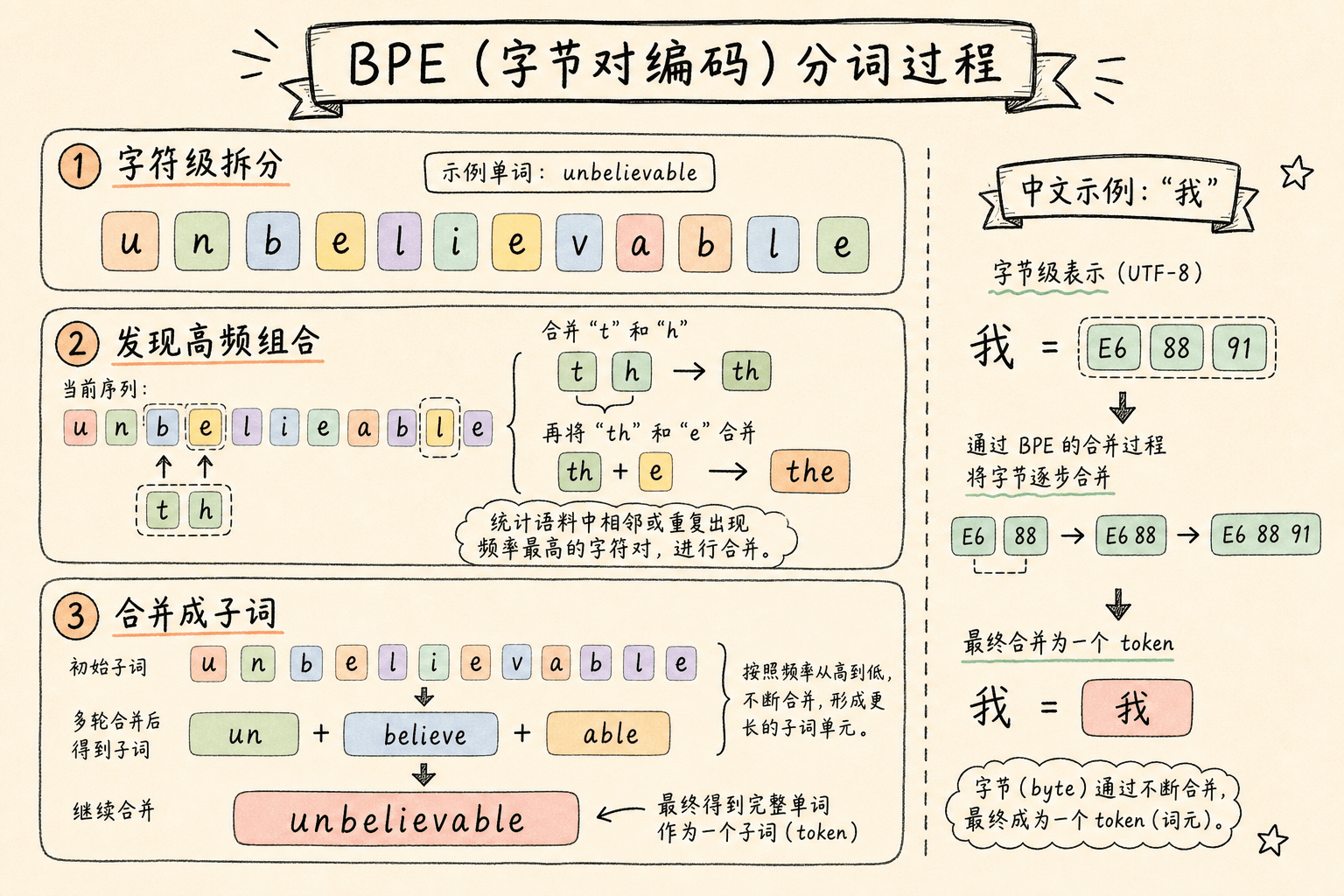
字节级 BPE:为什么没有”外语”被拒之门外
区别在于 BPE 的起点。早期的 BPE 以 Unicode 字符为起点——只能处理训练词表中出现过的字符。现代 LLM(GPT-4、LLaMA 3、Claude 系列)改用了字节级 BPE:起点是 256 个字节(0x00-0xFF),而非字符。
这个差异在支持多语言时至关重要:
- 第一层(字节):任何语言都能用 UTF-8 编码表示为字节序列。中文字”我”是
\xe6\x88\x91,阿拉伯字母”ا”是\xd8\xa7— 它们都是字节。 - 第二层(合并):BPE 从训练数据中发现高频字节组合(子词)。对于中文,
\xe6\x88\x91(”我”)作为一个整体频繁出现 → 被合并成一个 token。对于英语,”the”是高频模式 → 被合并成一个 token。 - 最终词表:同时包含”我”和”the”,因为它们在各自语言的训练数据中都足够高频。
因为起点是字节,所以没有语言是不可处理的。 这就是多语言支持的第一块基石。
Fertility Score:效率不公但可行
任何语言都能被分词,但效率差异很大。Fertility Score(生育率) 衡量每个词平均被切分成多少个 token:
| 语言 | Fertility(平均每个词的 token 数) | 说明 |
|---|---|---|
| 英语 | ~1.0 | 很多常见词是完整的单一 token |
| 中文 | ~1.5-2.0 | 常见词是完整 token,生僻词拆成字 |
| 日语 | ~2.0-3.0 | 混合文字系统增加 token 数 |
| 亚美尼亚语 | ~3.95 | 词表覆盖率低,大量拆解 |
用亚美尼亚语问同一个问题,模型需要处理近 4 倍的 token 数——推理更慢、成本更高、出错概率更大。但它仍然能处理。
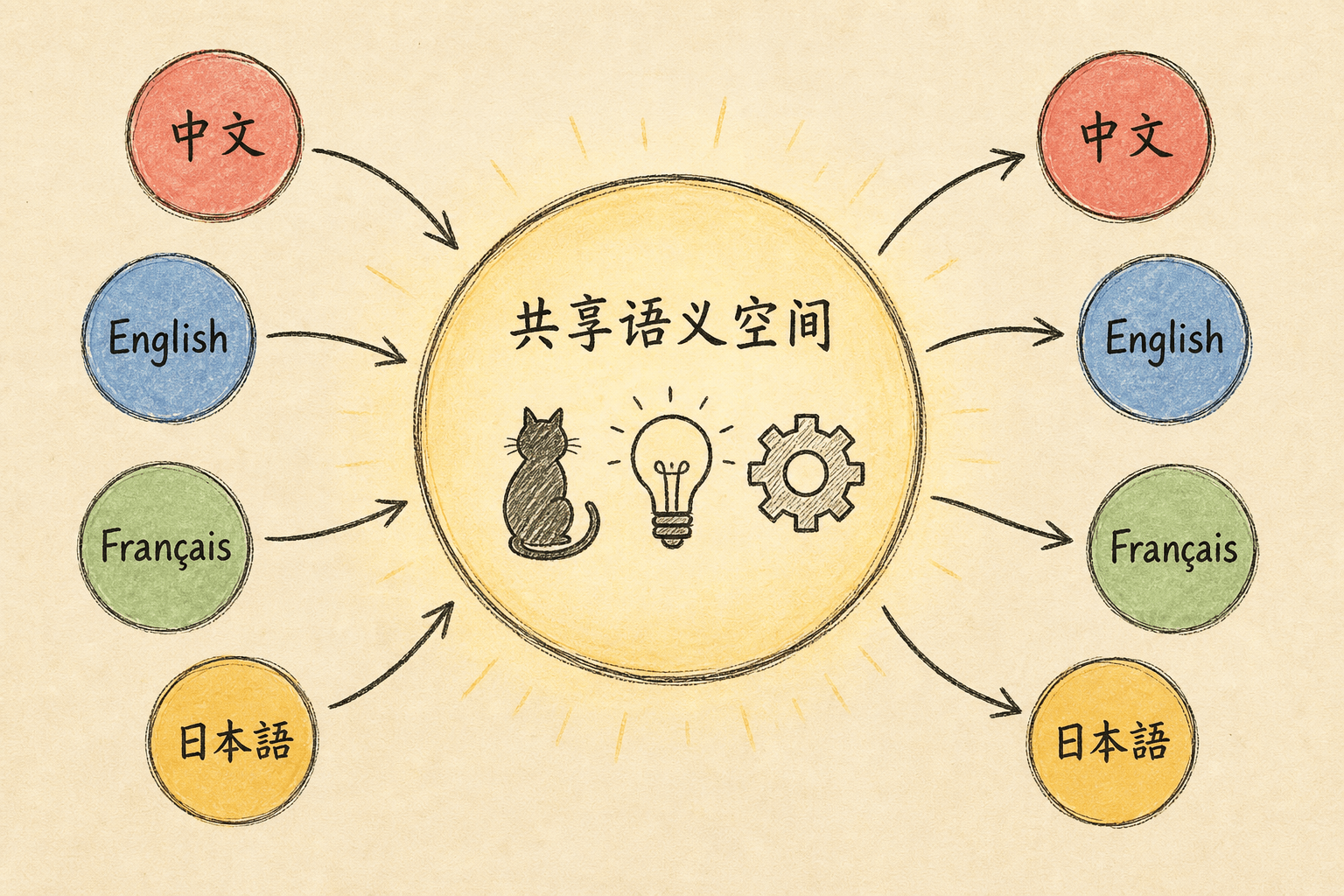
二、Shared Semantic Space:模型的”通用语”
Tokenization 解决了”如何让模型看到文本”,共享语义空间则解释”为什么模型能理解这些文本的含义”。
多语言数据迫使模型”去语言化”
LLM 的训练任务只有一个:给定前面的 token,预测下一个 token。当训练数据混有英文和中文时,模型会遇到一个有趣的局面:
英文语料告诉它:”cat is an” → 下一个是 “animal”
中文语料告诉它:”猫是” → 下一个是 “动物”
从 token 层面看,”cat” 和 “猫” 是两个完全不同的 ID,没有任何共享信息。但模型要预测的语义模式是同一个:一种动物,属于某一大类。如果模型分别维护两套知识(英文一套、中文一套),它需要双倍的参数来存储同一条知识,而且遇到新信息时还要同时更新两套——效率很低。
更高效的做法是:把 “cat” 和 “猫” 映射到同一个内部向量,把 “animal” 和 “动物” 映射到另一个向量。这样,模型只维护一套知识表示,两种语言共享使用。英文能用,中文也能用。
训练几亿条混合语料后,这种”合并同类项”的策略自然涌现——因为统一表示能让模型同时预测两种语言,且预测得更准。这就是共享语义空间的由来。
多个独立实验室的验证
三个独立团队从不同角度证实了共享空间的存在:
Anthropic(2025) 用”电路追踪”技术拆开了 Claude 的大脑。他们让 Claude 回答三个问题——英语”What is the opposite of small?”、法语和中文版本。结果发现,不管用哪种语言问,模型内部点亮的是同一组”脑区”:一个”small 概念”特征、一个”取反义”操作特征、一个”big 概念”特征。他们还做了因果实验:人为把”相反”操作特征换成”同义词”,所有语言的输出同时变成了同义词。语言只在进出模型时出现,模型内部处理的是与语言无关的概念。
Zeng 等人(COLING 2025) 追踪了训练过程中各语言在内部空间里的”坐标”变化。一开始,每种语言各自挤在角落。训练到中后期,各语言的坐标区域开始互相靠近、最终重叠——就像把不同颜色的颜料搅到一起,变成了均匀的颜色。
Wu 等人(2024) 发现共享空间不止跨越语言。代码 int x = 42、数学公式 42、以及对应的英文和中文,都指向同一个内部表示。这说明共享空间可能是 Transformer 架构本身的性质,而不只是多语言训练的副产品。
三、U 型语言熵:层间分工模式
共享语义空间不是均匀分布在所有层中的。层间分工在近年研究中被反复确认。
从 U-Shape 看三阶段流水线
Cross-Layer Transcoder(CLT,跨层转录器)——Transformer 可解释性领域的新技术——揭示了多语言处理的层间语言熵模式。
语言熵衡量神经元或层倾向于支持单一语言还是多种语言。熵越低越”专一”,熵越高越”通用”。语言熵在 Transformer 中的分布呈 U 型:
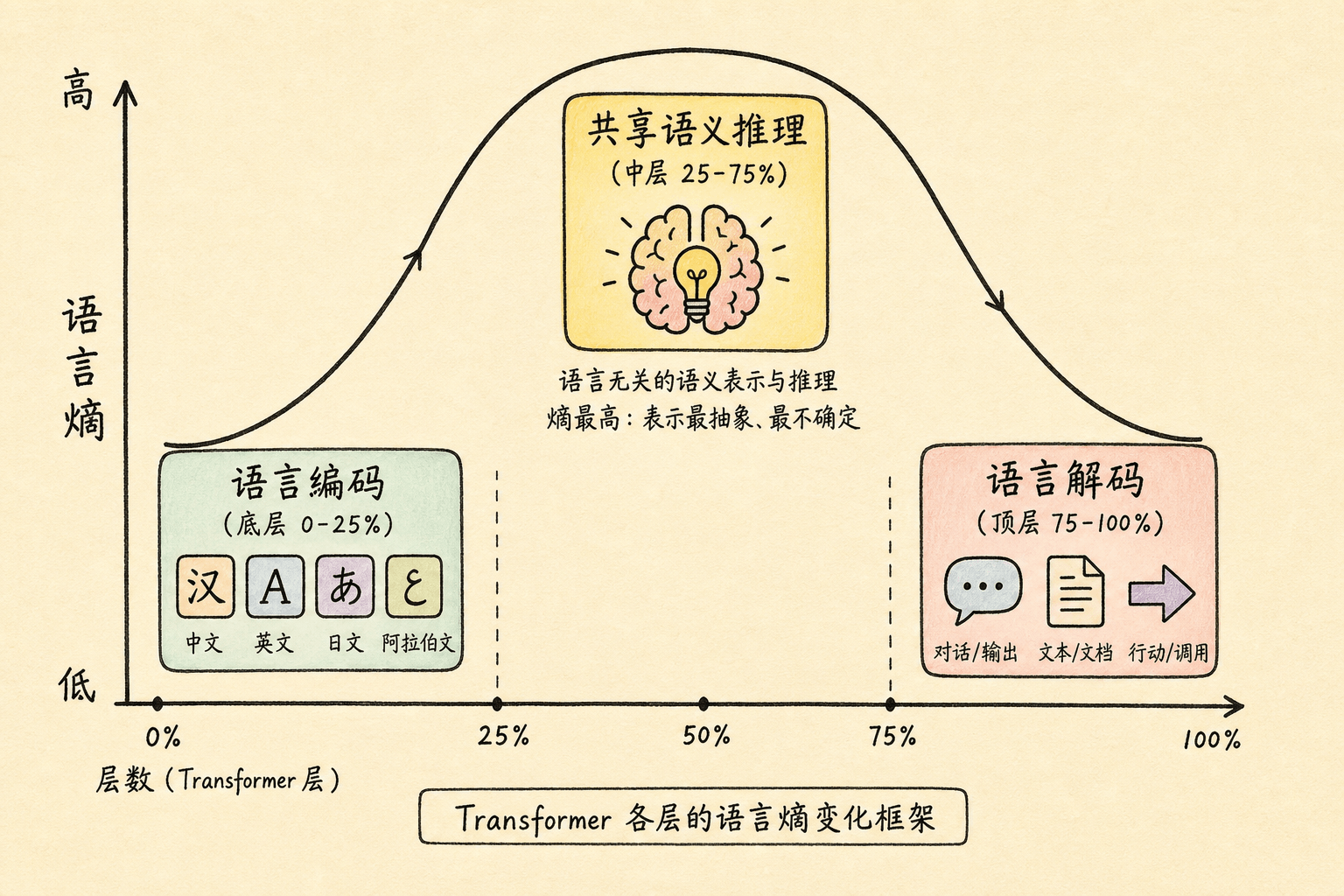
具体来说:
| 层范围 | 语言熵 | 功能 | 神经活动特征 |
|---|---|---|---|
| 底层 0-25% | 低 | 多语言理解与编码:将各语言的输入映射到共享语义空间 | 语言特异性 + 语言相关神经元占主导 |
| 中层 25-75% | 高 | 语言无关推理:所有语言共享同一计算回路 | 通用神经元占主导 |
| 顶层 75-95% | 低 | 输出空间转换:将共享表示投射回目标语言 | 语言特异性 + 语言相关神经元回升 |
| 输出层 | 最低 | 词汇选择:选择目标语言的词汇完成生成 | 语言特异性神经元达到峰值 |
需要足够深度才能涌现
Harrasse 等人(2026)发现:层间分工需要足够模型深度才能涌现。4 层的 TinyStories 模型中不存在语言分层模式。只有深度超过一定阈值,U 型语言熵才会自然出现——这也是早期浅层神经网络无法做到多语言泛化的原因。
英语是”内部枢纽”吗?
以英语为主训练的模型(如 LLaMA 系列),内部流程其实是这样的:
中文输入 → 先”翻译”成英语 → 用英语思考 → 再”翻译”回中文输出
Zhao 等人(NeurIPS 2024)做了一个实验来验证:把模型里负责识别语言的神经元关掉,非英语处理能力立刻崩了,但英语完全不受影响。这说明英语在模型内部是”默认语言”,其他语言要先”转成英语”才能被处理。
但这个结论有个重要限定:这是数据偏置造成的,不是架构必须如此。在平衡多语言模型(如 Aya-23)里,多种语言同时激活,没有英语独占的情况。更关键的是,完全不用英语数据训练的模型,同样能发展出跨语言共享表示。共享语义空间是 Transformer 的自然产物,英语的”枢纽地位”只是因为它训练数据最多。
四、神经元分工:从二元到三元
共享语义空间的实现机制,在神经元层面有更直接的答案。
传统二元分类的不足
早期研究将神经元简单地分成两类(二元分类):语言特异性神经元只对一种语言有反应(比如只在处理中文时活跃),通用神经元对所有语言都一样活跃(比如负责推理逻辑、常识的那部分)。但这种”非此即彼”的分法无法解释:为什么某些语言之间迁移效果好,另一些则差?
南京大学和微软亚洲研究院发表在 AAAI 2026(Oral)的论文给出了答案。
三元分类体系
他们提出的三元分类法将语言相关神经元细分为三类:
| 类型 | 激活特征 | 在模型中的占比 | 功能 |
|---|---|---|---|
| 语言特异性 | 仅在 1 种语言上高激活 | 较高(训练早期) | 处理输入输出形式,识别具体语言的语法结构 |
| 语言相关 | 在 2-9 种语言上高激活 | 中等(可训练增强) | 跨语言桥梁:捕捉语言群组间的共享模式(如罗曼语族的共享语法结构) |
| 通用 | 在所有(≥10种)语言上高激活 | 较高(训练后期) | 任务无关推理:逻辑、常识、数学推理 |
语言相关神经元是跨语言迁移的关键。它们形成”局部共享”结构:罗曼语族(法语、西班牙语、意大利语)的语言相关神经元高度重叠,形意文字系语言(中文、日语)共享另一组神经元,闪语族(阿拉伯语、希伯来语)又一组。
对齐训练改变神经元分布
多语言对齐训练(RLHF,基于人类反馈的强化学习、监督微调)对神经元分布的影响:
- 对齐前:语言特异性神经元占主导——模型”单语言特化”严重
- 对齐后:语言相关神经元显著增加。模型从”单语言特化”转向”多语言共享”结构
- 自发多语言对齐:即使只对少数语言进行对齐训练,未参与对齐的语言也能受益——因为语言相关神经元的共享范围在扩大
五、为什么能用中文输出英文知识
知识与语言相互分离
模型的知识存储在 FFN(前馈网络,负责存储和检索知识的层) 中,而语言的表达形式则由 Embedding(嵌入,负责把 token 变成向量的层) 和注意力模式控制。两者在大模型中相对独立。
打个比方:模型从英文数据中学到”Austin 是德克萨斯州的首府”这条知识。你用中文问”德克萨斯州的首府是哪里?”时,模型的内部过程是:
- 先把中文问题”翻译”成模型内部的通用语言
- 在中层找到那条关于 Austin 的知识——和英文提问找到的是同一条
- 再把答案”翻译”回中文输出
知识不分语言,只有输入和输出才分。所以英文数据训练出来的知识,中文照样能用。
六、局限与前沿
Tokenizer(分词器)的公平性
BPE 天然偏向训练数据中最丰富的语言。低资源语言的长 token 序列意味着:
- 推理速度慢数倍
- 出错概率更高
- 上下文窗口被低效占用
正在涌现的解决方案包括:
- 并行 Tokenizer:为每种语言独立训练 tokenizer,通过双语词典对齐索引
- Token Reuse(R-BPE,token 复用):在 token 间共享匹配的子序列
- 字节级模型(如 ByT5):完全跳过 tokenization,直接在字节级别处理
低资源语言的根本瓶颈
CLT 研究(2026)表明,低资源语言的问题不在共享语义空间,而在于:
- 顶层解码信号弱:模型难以将共享表示翻译回目标语言的词汇
- Tokenizer 偏置:低资源语言被切分成大量碎片 token
- 缺乏桥梁神经元:语言相关神经元不足以连接低资源和高资源语言群组
仅需约 400 篇高质量文档的微调,就能显著增强这些神经元通路(Zhao 等人,2024)。
多语言诅咒
Curse of Multilinguality(多语言诅咒) 指每增加一种训练语言,已有语言的性能会受到轻微损害。模型参数是固定的,要装更多语言,每种语言分到的”空间”就少了。
Google ATLAS 研究(2026,774 次实验,400+ 语言)量化了这种取舍:
- 语言数量翻倍:模型参数量需要增加 ×1.18,训练数据量增加 ×1.66
- 正协同效应:相似语言之间会互相帮助(如挪威语、瑞典语、德语都用拉丁字母且语法接近)
- 亲疏远近:差异大的语言之间几乎没有知识迁移(如阿拉伯语和日语)
七、总结
大语言模型能够支持几乎所有人类语言,是以下机制协同作用的结果:
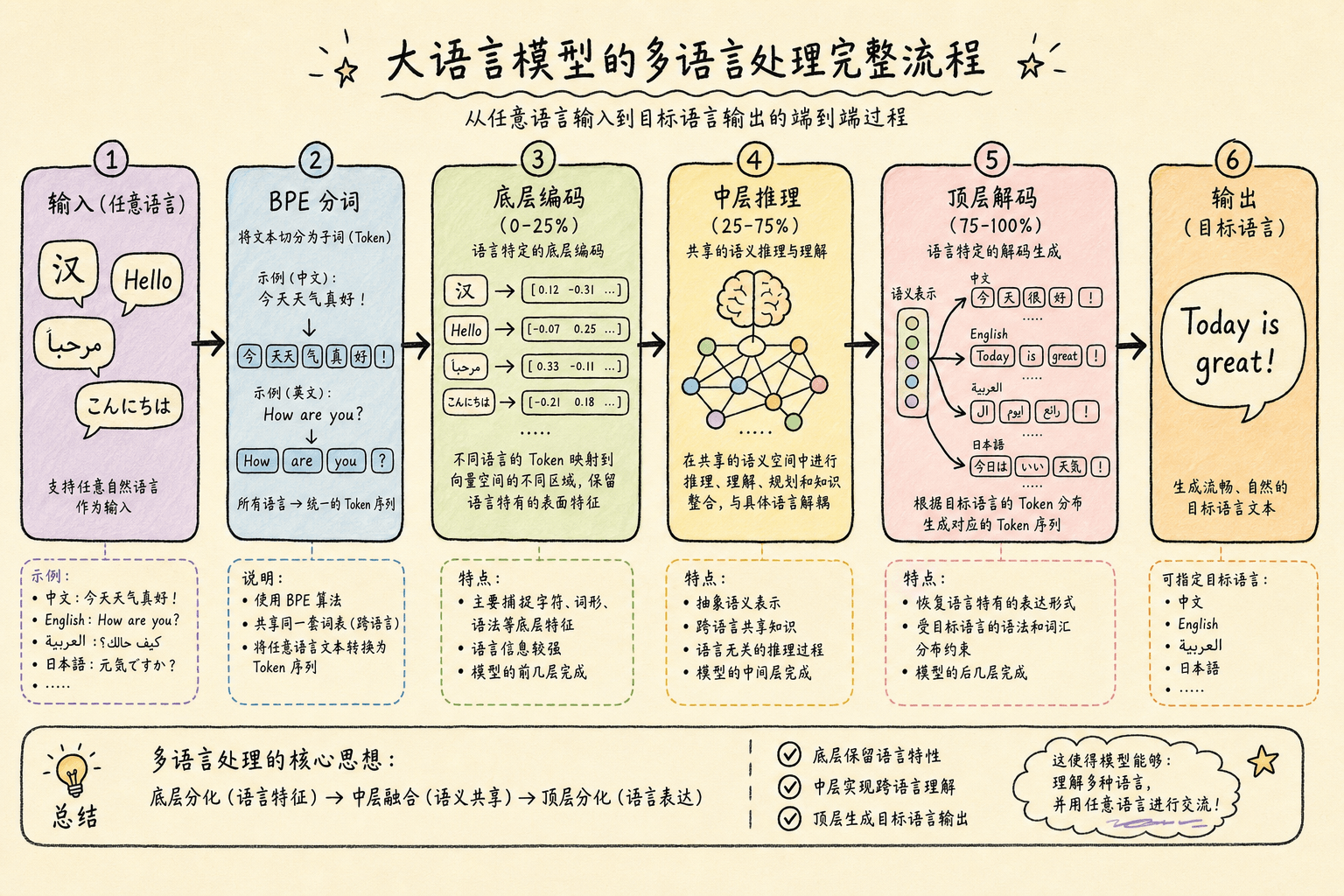
贡献这一能力的四个关键因素:
- 字节级 BPE:没有语言被拒之门外,所有语言都能用字节表示
- 共享语义空间:多语言训练迫使模型抽象出语言无关的概念表示
- 神经元三元分工:语言特异性、语言相关、通用神经元各司其职
- 层间编码流水线:编码-推理-解码的三阶段架构隔绝语言形式与语义内容
瓶颈已从”能否支持”变成”如何公平支持”——Tokenization 偏见、资源分配不均、英语中心的数据分布,是下一个需要解决的问题。
实际建议
如果你同时会中文和英文,用英文跟大模型交互通常效果更好。原因前面都讲过了:英文分词效率高、训练数据多、模型内部以英文为默认语言。尤其是在复杂推理、专业问答、代码编写等场景下,英文的优势更明显。
当然,中文在日常对话、翻译、写作等场景下已经足够好用,不必强求全换成英文。根据场景灵活切换,是最务实的做法。
参考来源
- Sennrich et al. “Neural Machine Translation of Rare Words with Subword Units”. ACL 2016. [arXiv:1508.07909]
- Zhao et al. “How do Large Language Models Handle Multilingualism?”. NeurIPS 2024. [arXiv:2402.18815]
- Zeng et al. “Converging to a Lingua Franca: Evolution of Linguistic Regions and Semantics Alignment in Multilingual LLMs”. COLING 2025.
- Wu et al. “The Semantic Hub Hypothesis: Language Models Share Semantic Representations Across Languages and Modalities”. 2024. [arXiv:2411.04986]
- Zhang et al. “How Does Alignment Enhance LLMs’ Multilingual Capabilities? A Language Neurons Perspective”. AAAI 2026 (Oral). [arXiv:2505.21505]
- Harrasse et al. “Tracing Multilingual Representations in LLMs with Cross-Layer Transcoders”. 2026. [arXiv:2511.10840]
- Anthropic. “On the Biology of a Large Language Model”. 2025. [arXiv:2505.23548]
- Trinley et al. “What Language(s) Does Aya-23 Think In?”. 2025.
- Google ATLAS Study: “Building AI in 400+ Languages”. 2026.
- Brinkmann et al. “Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages”. NAACL 2025.