前馈神经网络:大模型背后的"沉默支柱"
前馈神经网络:大模型背后的”沉默支柱”
如果你打开任何一个现代大语言模型(比如 GPT、Claude、DeepSeek)的技术白皮书,你会看到一个被反复提及的模块:Feedforward Neural Network,中文叫”前馈神经网络”,简称 FFN 或 FNN。
奇怪的是,媒体很少谈论它。大家津津乐道的是 Attention(注意力机制)——那个让模型能”看上下文”的神奇设计。但如果你把 Attention 比作大模型的”眼睛和耳朵”,那么前馈神经网络就是它的”大脑皮层”。没有后者,前者看到再多信息也无法”想明白”。
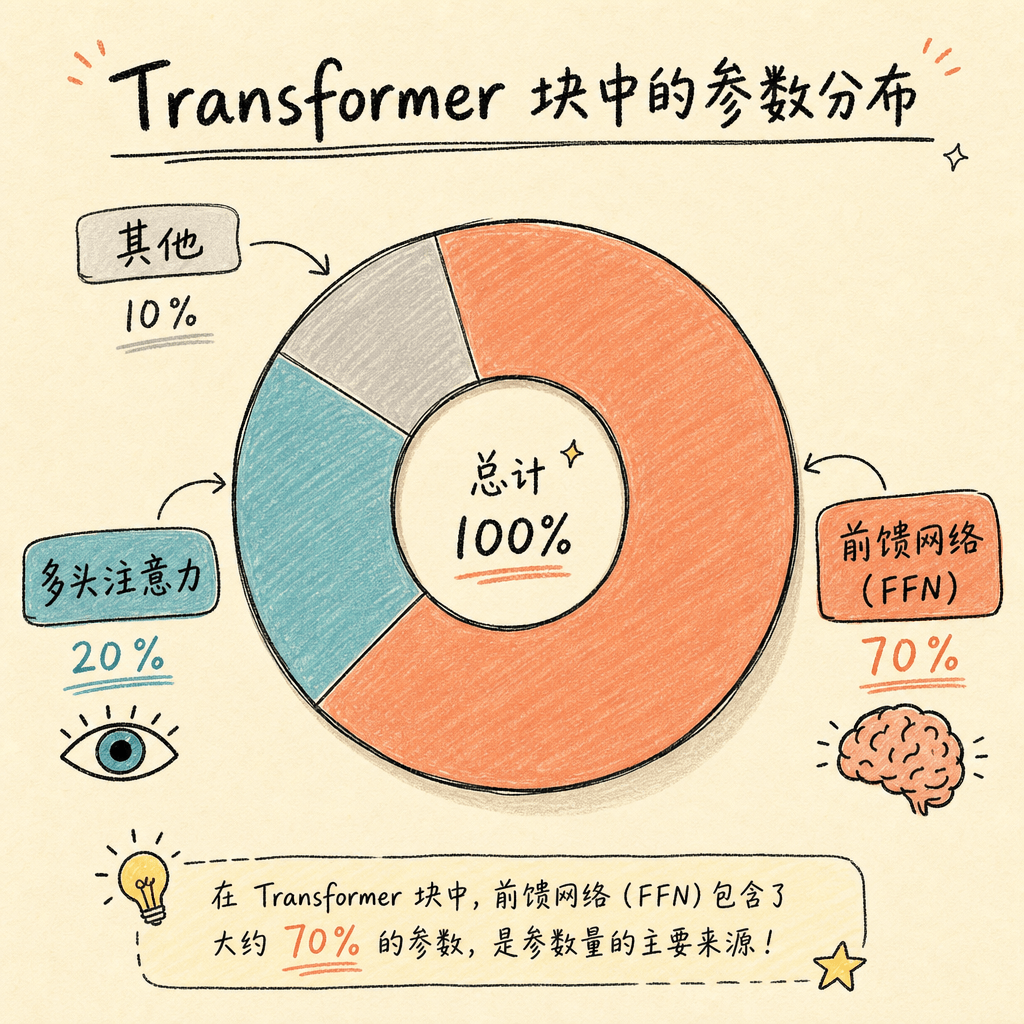
更让人惊讶的是,在一个标准的 Transformer 块里,FFN 占了约 60% 到 80% 的参数量。换句话说,当你听说某个模型有 700 亿参数时,其中有大约 400 多亿参数都藏在前馈神经网络里。
这篇文章会用尽量通俗的语言,讲清楚三件事:
- 前馈神经网络到底是什么?
- 为什么从 1958 年诞生至今,它依然是不可替代的?
- 为什么今天所有大模型都绕不开它?
一、一条被”证伪”又”复活”的技术 lineage
要讲清楚前馈神经网络,得从它的”祖先”——**感知机(Perceptron)**说起。
1.1 1958 年:第一个会学习的”人工神经元”
1958 年,心理学家 Frank Rosenblatt 发明了一个叫”感知机”的装置。它可以接收多个输入信号,给每个信号配一个”权重”,加起来之后做一个简单的判断:如果总和超过某个阈值,就输出 1;否则输出 0。
用今天的眼光看,这就像一个只会做”是非题”的裁判。
Rosenblatt 很兴奋,因为他证明了一件事:这个装置可以通过”看例子”来自动调整权重,学会区分两类事物。比如,给它看一堆猫和狗的图片(配上标签),它能慢慢学会一个边界,把猫和狗分开。
但这个边界有个致命的局限:它只能画一条笔直的分界线。
什么意思呢?想象你在一张纸上画了很多红点和蓝点。感知机能做的,只是拿一把直尺,在纸上划一条直线,把红点分到一边、蓝点分到另一边。如果红点和蓝点是”交错混杂”的——比如蓝点围成一个圈,红点在圈中间——那无论你怎么拿直尺划直线,都永远不可能把它们完美分开。
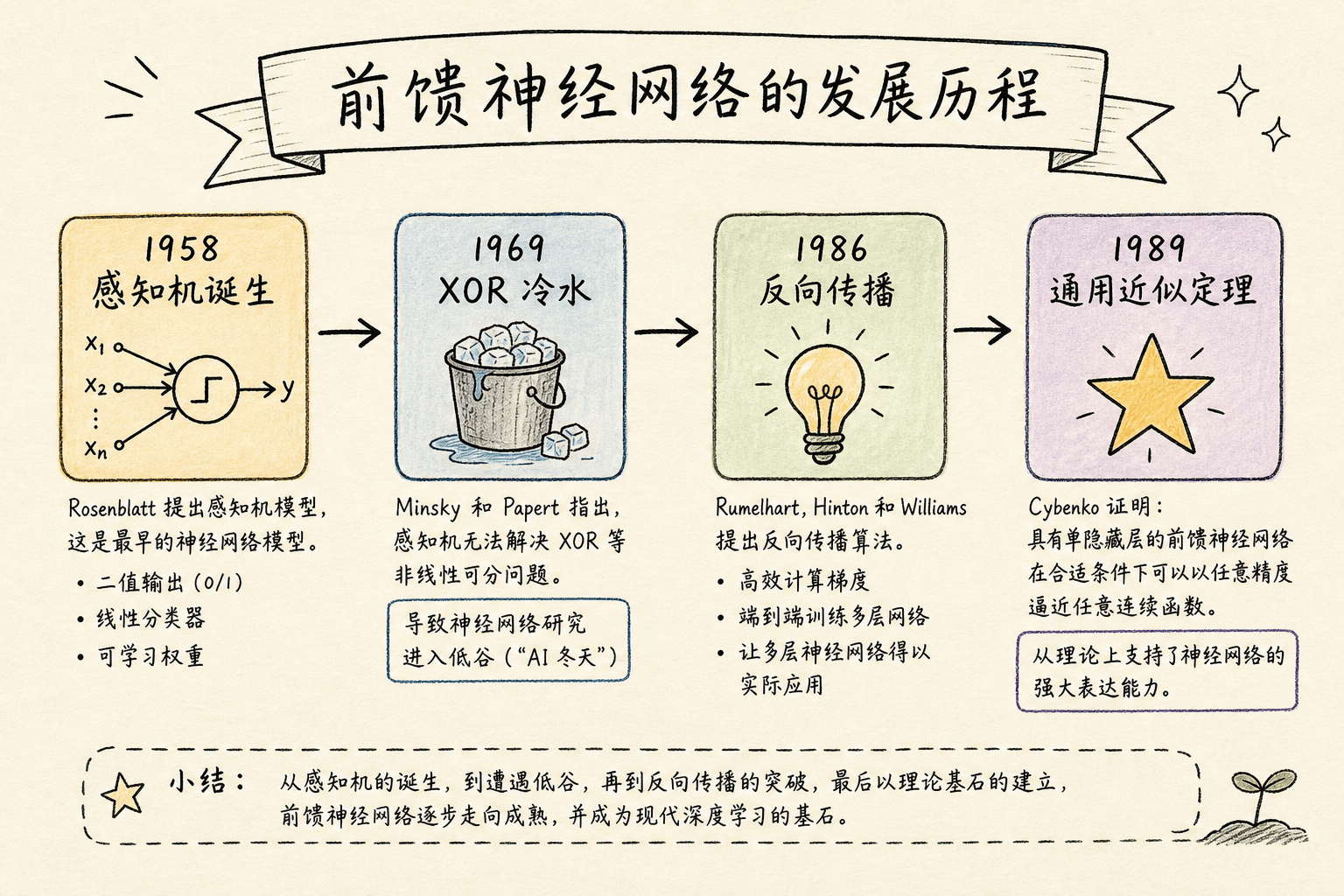
1.2 1969 年:一盆冷水
1969 年,MIT 的 Marvin Minsky 和 Seymour Papert 出版了一本书,叫《Perceptrons》。他们用一个极其简单的数学问题——XOR(异或)——把感知机打入了冷宫。
XOR 问题的规则很简单:
- 输入 (0, 0) → 输出 0
- 输入 (0, 1) → 输出 1
- 输入 (1, 0) → 输出 1
- 输入 (1, 1) → 输出 0
你没法用一条直线把输出为 1 的两个点和输出为 0 的两个点分开。感知机做不到。Minsky 和 Papert 证明了:单层感知机无法解决任何”非线性可分”的问题。
这盆冷水直接浇出了第一个人工智能寒冬。大家得出结论:神经网络这条路走不通。
1.3 1986 年:反向传播,让多层网络复活
关键突破发生在 1986 年。认知科学家 David Rumelhart、Geoffrey Hinton 和 Ronald Williams 发表了一篇论文,提出了反向传播算法(Backpropagation)。
他们的核心洞察很简单:既然一个神经元只能画直线,那为什么不把很多神经元叠在一起呢?
第一层神经元画一些简单的线,第二层把第一层的输出当作输入,再画一些线……叠得足够多,这些直线就能拼出任意复杂的曲线。
但问题是:怎么训练这种多层结构?每一层的权重怎么调?
反向传播算法的回答既优雅又粗暴:
- 让数据从输入层一路” forward(前向)”流到输出层,得到一个预测结果。
- 把预测结果和真实答案比一比,算出”误差”。
- 把这个误差从输出层反向传回输入层,沿途告诉每一层:”你的权重该往哪个方向调,才能让下次的误差变小。”
- 重复几万次、几十万次。
这个算法让”多层感知机(Multilayer Perceptron, MLP)”——也就是我们今天说的前馈神经网络——真正变得可训练、可实用。
1989 年,George Cybenko 证明了著名的通用近似定理(Universal Approximation Theorem):一个具有足够多神经元的前馈神经网络,可以逼近任意复杂的连续函数。这给前馈神经网络奠定了坚实的数学基础。
一句话总结这段历史:单层感知机像一个人做判断,能力有限;前馈神经网络像一群人分层做判断,叠得越深,能力越强。
二、前馈神经网络到底是什么?
2.1 核心特征:数据只往一个方向流
“前馈”两个字已经说清了它的本质:数据从输入层进入,经过一层层隐藏层,最后到达输出层,整个过程没有回头路、没有循环。
这和人的神经系统有点像——感觉信号从皮肤、眼睛传入,经过脊髓、脑干、大脑皮层的一层层处理,最后变成动作指令传出去。虽然真实的生物神经有更多反馈回路,但前馈神经网络抓住了最核心的一层一层加工的思想。
2.2 工厂流水线的类比
想象一个加工厂:
- 输入层:原材料入口。比如你要识别一张手写数字图片,输入层就是图片的每个像素值。
- 隐藏层:加工车间。每一层都有很多”工人”(神经元),每个工人只做一件事:把上一层的输出拿过来,各自乘以一个权重,加起来,然后过一个”开关”。
- 输出层:成品打包。比如 10 个出口,分别代表数字 0 到 9,哪个出口的数值最高,模型就认为这张图片是哪个数字。
2.3 激活函数:那个不可或缺的”开关”
如果没有”开关”,前馈神经网络就废了。
为什么这么说?假设你有一个两层的网络:第一层做线性变换,第二层也做线性变换。但两层线性变换叠在一起,本质上仍然只是一个线性变换。数学上,$W_2(W_1x + b_1) + b_2$ 完全可以合并成一个新的线性函数 $W’x + b’$。
这意味着,无论你叠多少层,如果没有非线性,你依然只能画直线——和 1958 年的单层感知机没有区别。
激活函数就是打破线性的关键。它像一个非线性的开关:
- ReLU:输入为正就原样通过,输入为负就掐死(变成 0)。简单、高效、好用。
- Sigmoid/Tanh:把任意数值压缩到 0
1 或 -11 之间。早期常用,但后来发现容易导致”梯度消失”(训练到后面几乎学不动),所以被 ReLU 取代。 - GELU/SwiGLU:现代大模型常用的更平滑的变体。
没有激活函数,再深的网络也只是一层纸老虎。
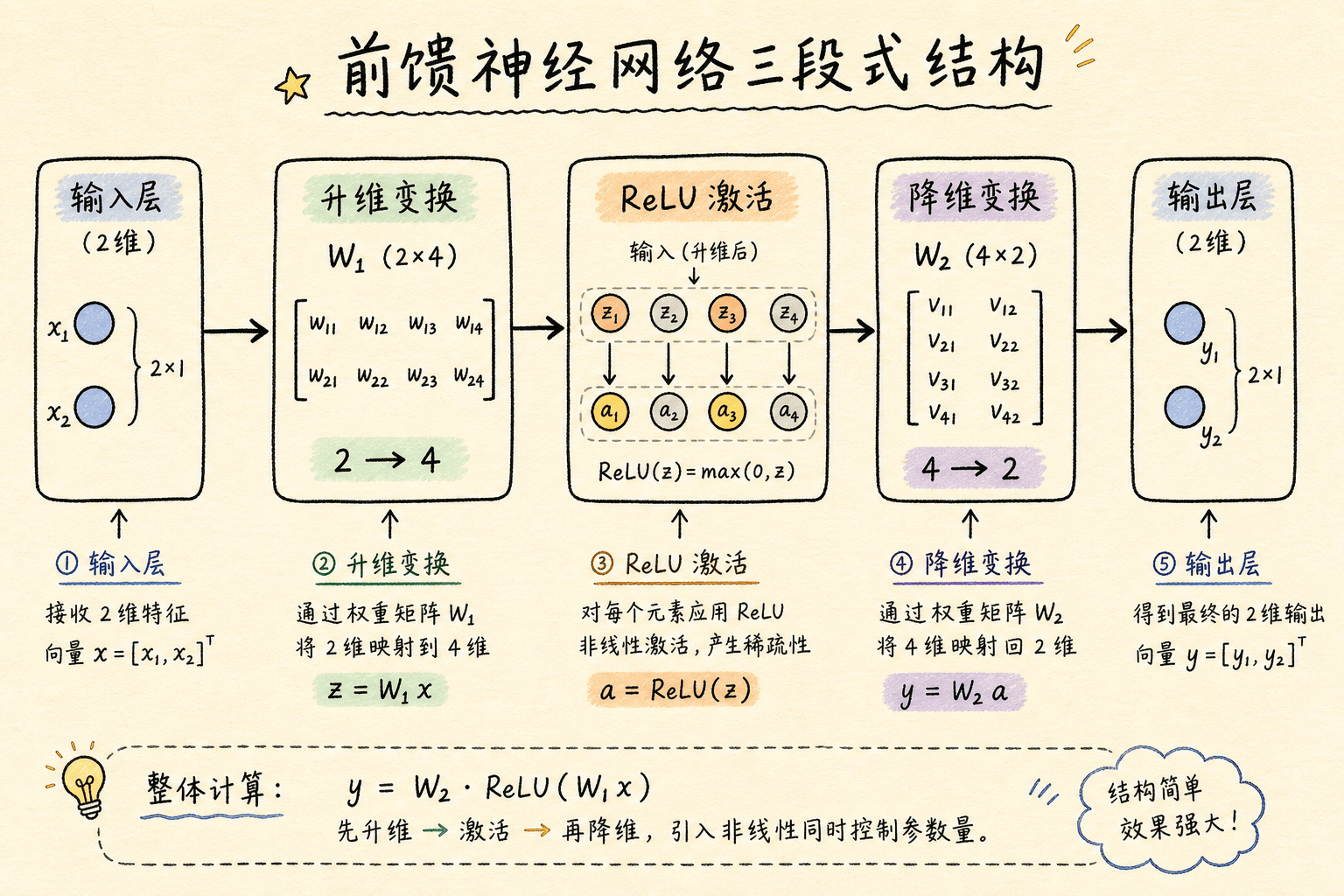
2.4 一个具体的数值例子
假设你有一个极简的前馈网络,输入维度是 2,隐藏层维度是 4,输出维度是 2。
输入向量:$x = [1.0, 2.0]$
第一步(升维):$x$ 和一个 $2 \times 4$ 的权重矩阵 $W_1$ 相乘,再加上偏置 $b_1$,得到一个 4 维向量:
$$z_1 = [3.5, -1.0, 0.5, -2.0]$$
第二步(激活/ReLU):把负数掐死:
$$z_2 = [3.5, 0.0, 0.5, 0.0]$$
注意,4 个维度里只有 2 个被”点亮”了。这就是稀疏激活——模型只关注当前输入最相关的特征方向。
第三步(降维):$z_2$ 和一个 $4 \times 2$ 的权重矩阵 $W_2$ 相乘,得到输出:
$$\text{输出} = [2.25, 3.25]$$
这个”先升维、再激活、后降维”的三段式结构,正是现代 Transformer 中 FFN 的标准模板。
三、为什么大模型绕不开前馈神经网络?
现在进入核心问题。今天的 AI 大模型——无论是 GPT-4、Claude、还是开源的 Llama、DeepSeek——底层架构几乎都是 Transformer。而一个 Transformer 块里只有两大核心组件:
- Multi-Head Attention(多头注意力):负责”看谁”
- Feed-Forward Network(前馈网络):负责”想明白”
Attention 机制解决了”让模型看到上下文”的问题,这是一个巨大的突破。但 Attention 本身有个隐藏缺陷:它本质上是线性操作的组合。无论你堆多少层 Attention,如果没有 FFN 的介入,整个模型仍然近似于一个复杂的线性系统。
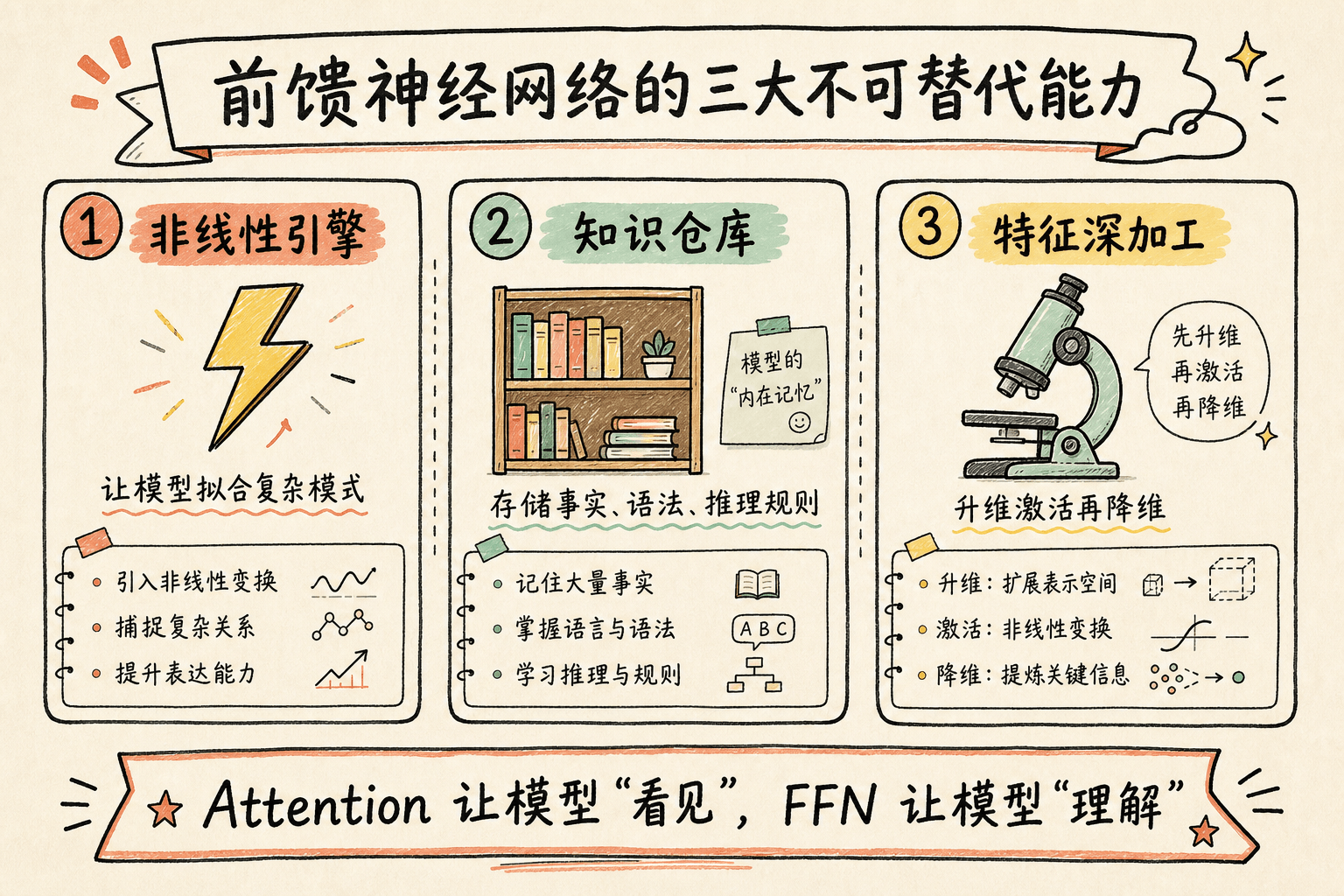
FFN 的存在,弥补了 Attention 的三个致命短板。
3.1 短板一:非线性能力
Attention 的核心运算是”加权求和”——给不同位置的词分配不同的权重,然后求和。这里会用到一个叫 Softmax 的操作,它把一组分数转换成一组加起来等于 1 的”比例”(类似把考试分数换算成百分比排名)。但即便如此,Attention 的整体运算本质上仍然是一系列线性变换的组合,缺乏真正的非线性表达能力。
FFN 通过”升维 + 激活函数 + 降维”的三段式结构,引入了模型中最主要的非线性来源。没有它,Transformer 就只是一个庞大的线性回归模型,根本拟合不了人类语言那种复杂、跳跃、充满例外和隐喻的模式。
2025 年 Johns Hopkins 的 Isaac Gerber 做了一个非常直观的实验。他用标准的 GPT-3 Medium 架构(24 层,1024 维,约 3.23 亿参数)作为 baseline,然后只改动 FFN 的层数:
| FFN 层数 | Transformer 块数 | 总参数量 | 训练损失(Booksum) |
|---|---|---|---|
| 3 层 | 10 | 3.14 亿 | 4.208 |
| 2 层(标准) | 24 | 3.23 亿 | 4.259 |
| 1 层 | 24 | 1.47 亿 | 4.405 |
| 0 层(去掉 FFN) | 24 | 1.21 亿 | 4.610 |
结果触目惊心:完全去掉 FFN 后,训练损失从 4.259 暴涨到 4.610——模型的表现几乎崩盘。更妙的是,把 FFN 加深到 3 层、同时减少 Transformer 块数到 10 个,参数量更少、训练时间更短(快 13%),但性能反而超过了标准配置。
这个实验告诉我们:FFN 的质量和深度,对模型能力的影响完全不亚于 Attention。
3.2 短板二:知识存储
你可能听说过,大语言模型本质上是在”压缩互联网”。但压缩进去的知识存在哪里?
研究表明(Geva et al., 2021),Transformer 中绝大部分事实性知识——比如”巴黎是法国的首都”、”水的化学式是 H₂O”——都存储在 FFN 的权重矩阵里。
FFN 可以被理解为一种键值记忆(Key-Value Memory):
- 第一层权重 $W_1$ 像一把把”钥匙”,负责识别输入中的特定模式(比如看到”巴黎”这个词)。
- 第二层权重 $W_2$ 像一个个”抽屉”,里面存放着与钥匙对应的知识(比如”法国首都”)。
当你问模型”巴黎是哪个国家的首都?”时,Attention 负责把问题中的词关联起来,而 FFN 负责从它庞大的”抽屉库”里调出正确的答案。
在一个标准的 Transformer 里,FFN 的隐藏层维度通常是模型维度的 4 倍(比如模型是 4096 维,FFN 中间层就是 16384 维)。这个巨大的中间层,本质上就是一个超大规模的”记忆槽”阵列。隐藏层越大,模型能记住的事实和模式就越多。
这也是为什么 FFN 占了模型总参数量的 60% 到 80%。它不只是”加工厂”,更是”图书馆”。
3.3 短板三:特征的深加工
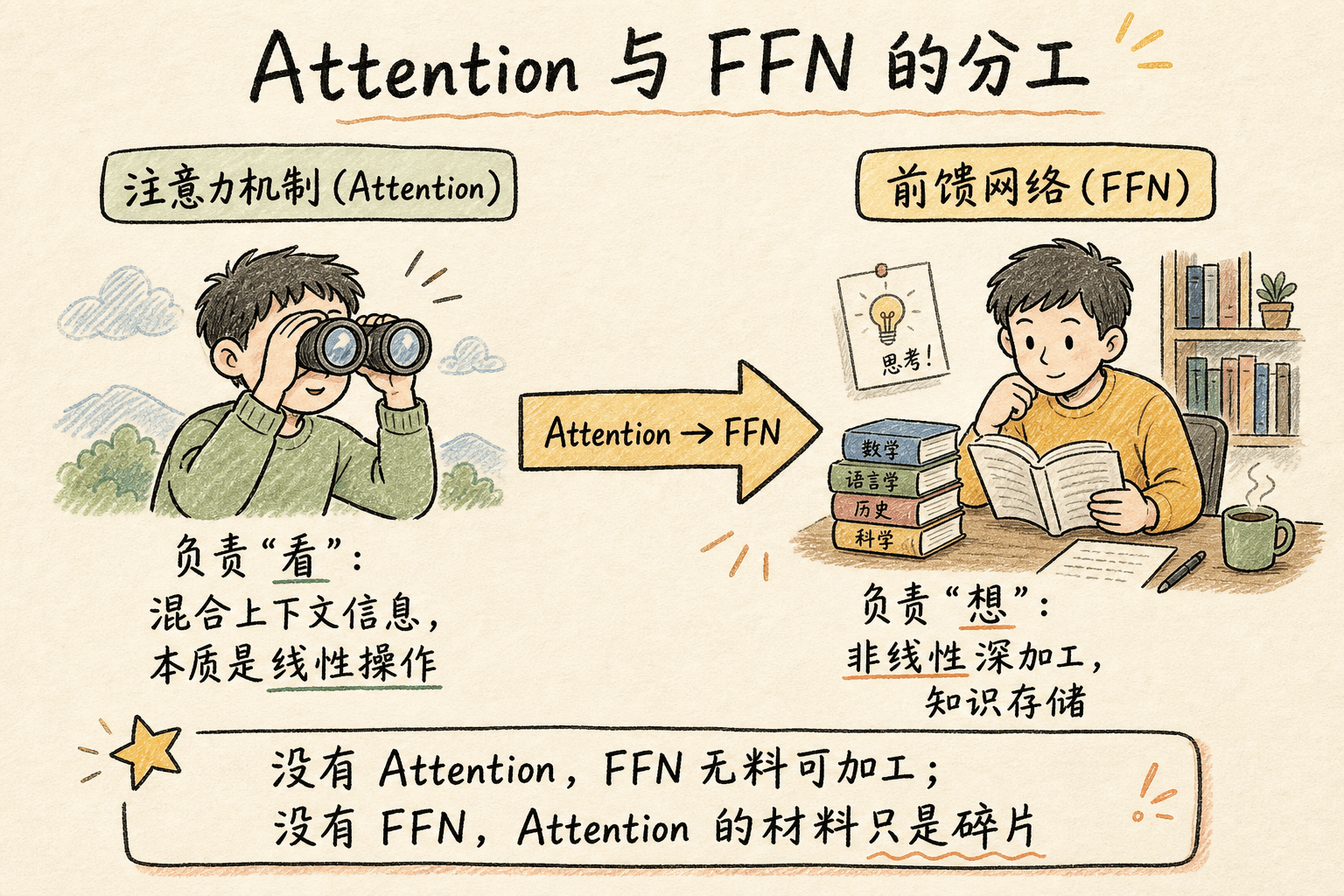
Attention 的工作是”混合信息”——让每个词都能”看到”上下文中的其他词。但混合完之后,这些信息的”语义深度”还不够。
FFN 的工作是”精加工”——对混合后的每个词向量做独立的非线性变换,把它映射到一个更适合下游任务(比如预测下一个词、翻译、推理)的特征空间。
用一个类比:
- Attention 是采访部记者。它跑遍全城,把各方信息收集到一个编辑室。
- FFN 是资深编辑。它独自坐在桌前,把记者交来的原始材料消化、提炼、赋予深度,写成一篇有洞察力的报道。
没有记者,编辑无料可写;但没有编辑,记者的材料只是一堆未经消化的碎片。
3.4 为什么是先升维、再降维?
你可能还有一个疑问:FFN 为什么要把向量从 512 维升到 2048 维,再降回 512 维?这不是多此一举吗?
恰恰相反,这是 FFN 最核心的设计智慧。
升维的目的,是为了”腾挪空间”。
低维空间就像一个小房间,不同的概念挤在一起,很容易互相干扰。高维空间就像一个大仓库,有无数个”货架”,每个货架可以放一种独立的模式。模型可以在高维空间里把不同的语义特征”摊平”开,互不打扰。
配合 ReLU 的稀疏激活,升维后的效果更明显:输入一个向量,只有一小部分货架被”点亮”,其余的都保持为零。这让模型可以非常精准地调用特定的知识,而不是把所有知识搅成一锅粥。
降维的目的,是为了”回归统一格式”。
Transformer 是一个层层堆叠的架构。FFN 的输出要成为下一层 Attention 的输入,所以维度必须和输入一致(比如都是 512 维)。降维就像一个标准化包装,让不同层之间的”接口”保持兼容。
同时,降维也是一个”信息提炼”的过程:从海量高维特征中,筛选出最核心、最紧凑的表达,传递给下一层。
升维是”展开细想”,降维是”收敛总结”。
四、常见误区
在理解了 FFN 的本质之后,我们再来澄清几个常见的误解。
误区 1:”Attention Is All You Need” = Attention 是全部
2017 年 Google 发表 Transformer 论文的标题是《Attention Is All You Need》,这导致很多人误以为 Attention 是 Transformer 唯一重要的部分。
但正如 Gerber 2025 年的论文标题所反驳的:《Attention Is Not All You Need: The Importance of Feedforward Networks》。实验证明,去掉 FFN 的 Transformer 性能暴跌。Attention 解决的是”信息从哪来”的问题,FFN 解决的是”信息怎么被理解和加工”的问题。两者缺一不可。
误区 2:模型层数越多越好
很多人天然觉得,神经网络叠得越深越厉害。这在一定程度上是对的,但并非没有代价。
更多的层意味着:
- 需要更多的训练数据(否则模型会”过拟合”,死记硬背而不是真正学会规律)
- 需要更多的计算资源
- 更深的网络更容易出现”梯度消失”或”梯度爆炸”,训练不稳定
Gerber 的实验甚至发现了一个反直觉的结果:用更深的 FFN(3 层)配合更少的 Transformer 块(10 个),比标准配置(2 层 FFN + 24 个块)效果更好、训练更快。 这说明架构的设计是”深度”和”宽度”之间的权衡,不是无脑堆层数。
误区 3:FFN 只是”辅助模块”
这是一个最危险的误解。FFN 不仅不是辅助模块,它实际上是 Transformer 的参数担当和知识主仓。
- 参数量:占 60%–80%
- 非线性来源:几乎是唯一的
- 知识存储:事实、语法、推理模式的主要载体
- 特征加工:将 Attention 的”上下文混合”转化为”深度语义”
如果 Attention 是 Transformer 的”交通系统”,FFN 就是它的”工业基地”。没有工业基地,交通再发达也只是空跑。
五、总结:为什么大模型绕不开它?
前馈神经网络从 1958 年的感知机一路走来,经历了被否定、被复活、被泛化、被深化的过程。今天,它以 FFN 的形态存在于每一个 Transformer 块中,成为大语言模型不可或缺的三大支柱之一(另外两个是 Attention 和残差连接)。
大模型之所以”绕不开”前馈神经网络,归根结底是因为三个不可替代的能力:
- 非线性引擎:没有 FFN,整个模型退化为线性系统,无法拟合真实世界的复杂模式。
- 知识仓库:模型学到的事实、语法和推理规则,绝大部分存储在 FFN 的权重中。
- 特征深加工:通过”升维激活再降维”,将 Attention 混合后的信息提炼为有深度的语义表达。
Attention 让模型”看见”,FFN 让模型”理解”。
从 MLP 到 Transformer FFN,变的是规模和细节,不变的是那个最朴素的原理:把很多简单的判断单元分层叠在一起,配合非线性激活,就能逼近任意复杂的函数。
这也是为什么,无论未来的大模型架构如何演变——MoE(混合专家)、Mamba、RWKV——前馈神经网络或其变体,始终是最核心的构件之一。它可能换了个名字、换了个形状,但那个”分层加工 + 非线性变换”的灵魂,从未离开。
六、延伸阅读
如果你想继续深入,以下资源是最优质的起点:
《Attention Is Not All You Need: The Importance of Feedforward Networks in Transformer Models》(Gerber, 2025)
- 直接通过实验证明了 FFN 的重要性,反驳了”Attention 万能论”。
- 最佳起点:如果你想了解 FFN 在 Transformer 中的定量作用。
《Learning representations by back-propagating errors》(Rumelhart, Hinton, Williams, 1986)
- 反向传播算法的奠基论文,让多层神经网络成为现实。
- 最佳起点:如果你想理解现代深度学习的历史原点。
《Transformer Feed-Forward Layers Are Key-Value Memories》(Geva et al., 2021)
- 提出 FFN 作为键值记忆的理论,解释了模型存储知识的方式。
- 最佳起点:如果你想理解 FFN 如何成为大模型的”记忆体”。
3Blue1Brown 的《Neural Networks》系列视频
- 可视化讲解神经网络的本质,极其直观。
- 最佳起点:如果你更习惯通过图像和动画来建立直觉。
《深度学习的数学原理》系列(CSDN, xiaolaji600)
- 中文资源中极少见的、从数学角度逐步拆解 Transformer 各组件的系列文章。
- 最佳起点:如果你想用中文深入理解 FFN 的升维降维逻辑。