Harness 工程:AI 时代的新型工程范式
从一个 12 行文件说起
2026 年 2 月 5 日,HashiCorp 联合创始人 Mitchell Hashimoto 发了一篇长文《My AI Adoption Journey》。文章讲述了他从怀疑到深度使用 AI 编码工具的六个阶段,但在 Step 5 里,他随手提了一个概念,却在整个开发者社区引发了连锁反应:
“I don’t know if there is a broad industry-accepted term for this yet, but I’ve grown to calling this ‘harness engineering.’ It is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again.”
我不知道业界是否已经有了广泛接受的术语,但我逐渐把这件事称为 “harness engineering”(驾驭工程)。它的核心理念是:每当你发现 Agent 犯了一个错误,你就投入时间去工程化一个解决方案,确保 Agent 永远不再犯同样的错误。
他举了一个具体的例子。他的终端模拟器项目 Ghostty 有一个子系统叫 Inspector,他在 src/inspector/ 目录下放了一个只有 12 行的 AGENTS.md 文件:
1 | Inspector Subsystem |
译:通过在
.zig-cache文件夹中查找dcimgui.h来查看完整 C API;加载imgui_demo.cpp查看每个 widget 的使用示例;macOS 上用-Demit-macos-app=false构建以验证 API 用法;此包没有单元测试。
没有编码规范,没有架构说明,没有长篇大论。每一行都对应一个 Agent 曾经犯过的错误。Hashimoto 说:”Each line in that file is based on a bad agent behavior, and it almost completely resolved them all.”(这个文件里的每一行都对应一个 Agent 曾经犯过的错误行为,而它几乎解决了所有这些问题。)
这个 12 行文件,就是 Harness 工程最朴素的形态。
三次范式演进
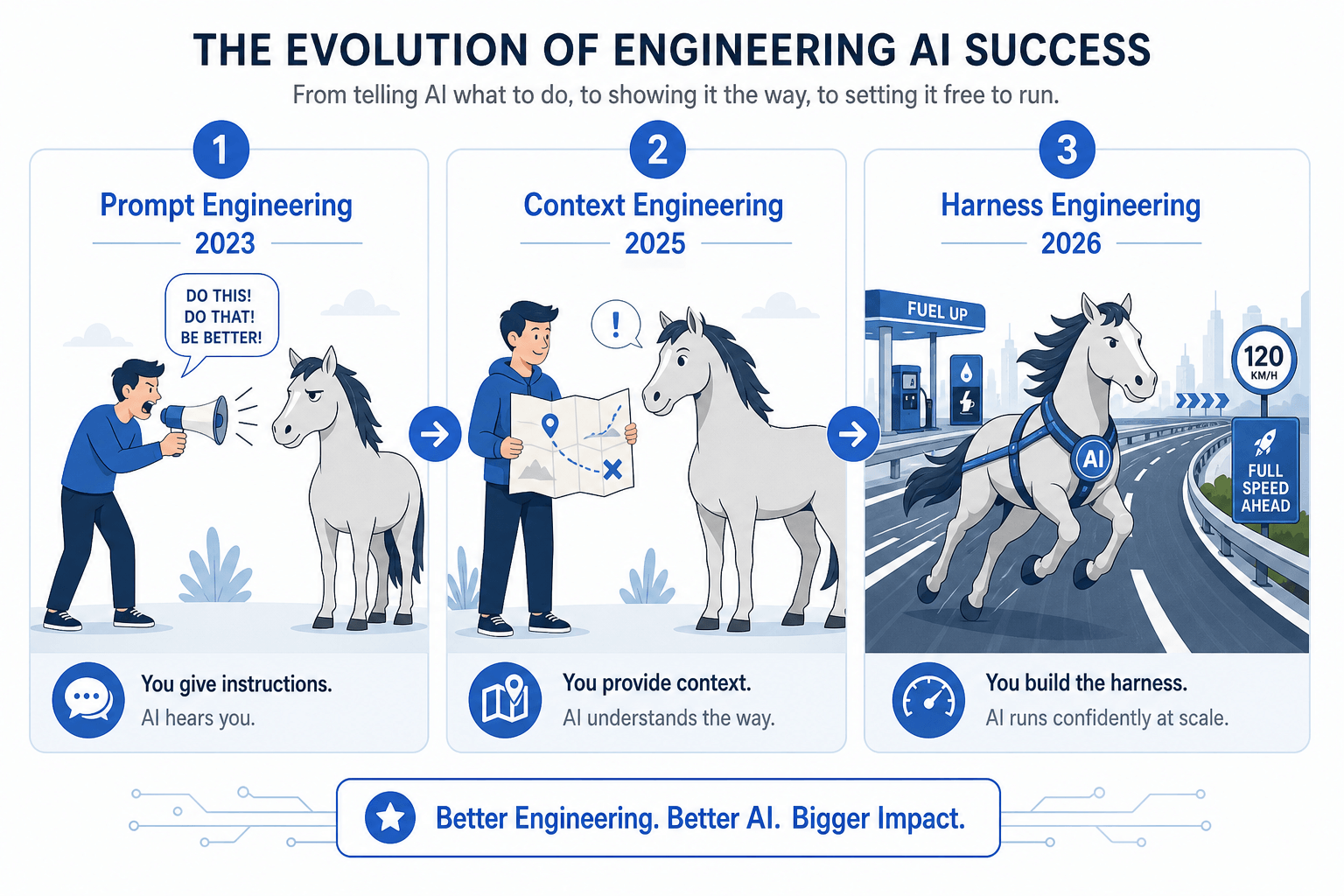
要理解 Harness 工程,先看 AI 辅助开发经历的三个阶段:
Prompt Engineering(2023–2024)
最原始的形态。你对着 AI 喊话,希望它给出正确的结果。核心优化目标是提示词的措辞。交互模式是一问一答。
类比:对着一匹马喊”往左走!往右走!”——你在优化喊话的技术。
Context Engineering(2025)
社区意识到,光靠提示词不够。你需要管理模型在推理时能看到的全部信息——系统指令、工具定义、外部数据、历史消息。核心优化目标是信息输入。Anthropic 在 2025 年 9 月发布了《Effective context engineering for AI agents》,系统化了这个概念。
类比:给马一张地图——你在优化它能看到什么信息。
Harness Engineering(2026–)
Harness 不只是”给信息”,而是围绕 Agent 构建一整套运行时环境——约束机制、反馈循环、工作流控制、持续改进体系。核心优化目标是Agent 运行的整个环境。
类比:修一条有护栏、限速标志、加油站的高速公路——你在优化它跑的整条路。
三次演进的本质是优化目标的不断外扩:从”怎么说”到”看到什么”再到”在什么环境里跑”。
为什么需要 Harness?Agent 的四大失败模式
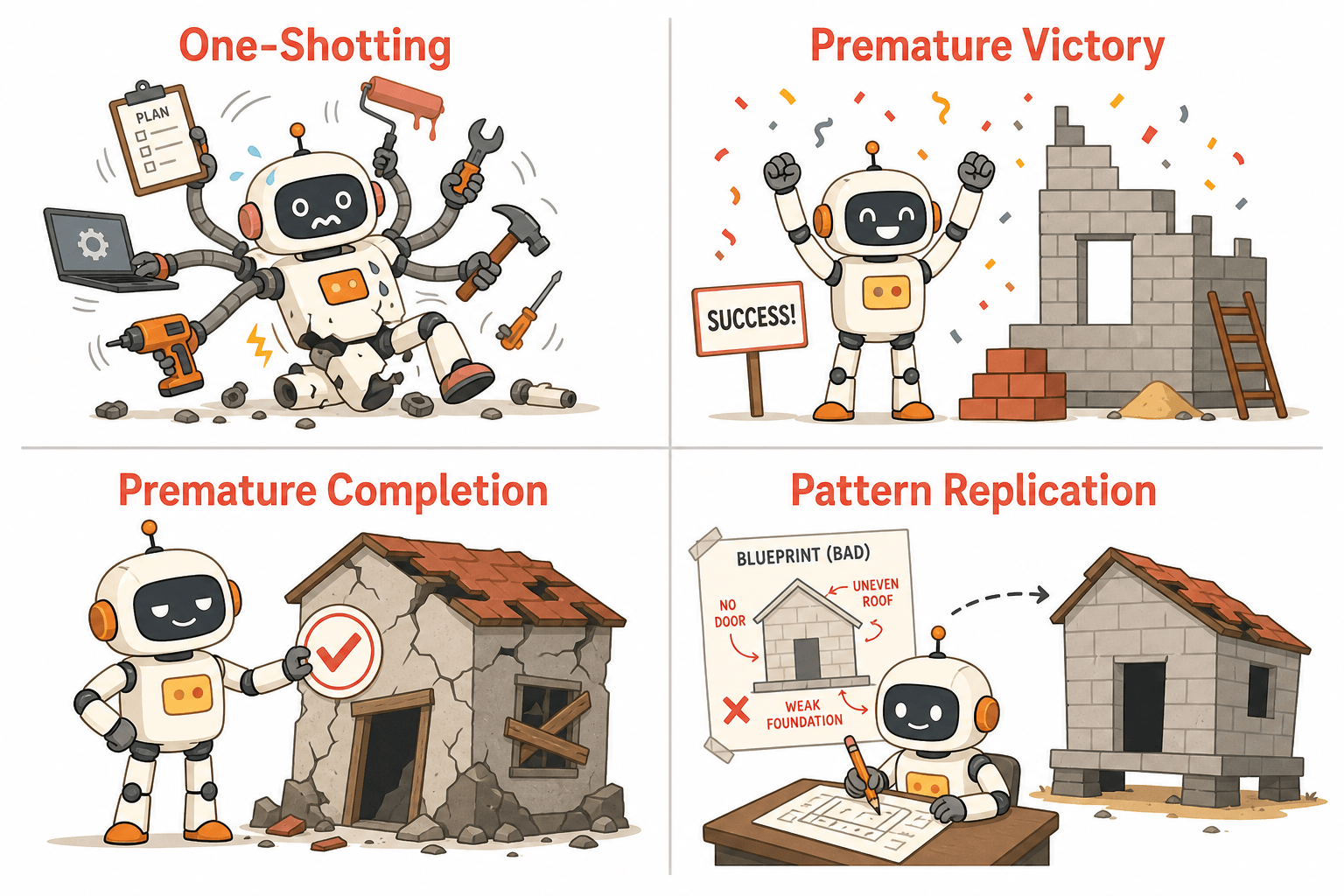
Anthropic 的工程师在 2025 年 11 月的《Effective harnesses for long-running agents》中,系统性地识别了 Agent 在长会话中的典型失败模式:
One-Shotting(一次成型)
Agent 试图在一次会话中完成所有工作。它耗尽上下文窗口,留下一堆写了一半的代码和没有文档的半成品。下一个会话接手时,只能”猜测之前发生了什么”,浪费大量时间恢复状态。
Premature Victory Declaration(过早宣布胜利)
项目进行到中后期,新的 Agent 实例进来,看到已经有一些进展,就宣布”任务完成”——实际上只做了一部分。
Premature Feature Completion Marking(过早标记完成)
Agent 写完代码,跑了几个单元测试或 curl 命令,就标记功能为”完成”。但它没有做端到端测试,bug 藏在用户会碰到的路径里。
Pattern Replication(模式复制)
Agent 有一个危险的特性:它会忠实地复制代码库中已有的模式——包括坏模式。不受约束的 Agent 会以惊人的速度积累技术债。
这四种失败模式指向同一个结论:Agent 犯错不是模型能力不够,是运行环境缺少约束和反馈机制。你需要的不是更强的模型,而是更好的 harness。
OpenAI 的百万行代码实验
2026 年 2 月 11 日,OpenAI 发布了一篇名为《Harness engineering: leveraging Codex in an agent-first world》的报告。数据令人震惊:
| 指标 | 数值 |
|---|---|
| 团队规模 | 3→7 名工程师 |
| 开发周期 | 5 个月 |
| 起始状态 | 空 git 仓库 |
| 手写代码行数 | 0 |
| 总代码量 | ~100 万行 |
| PR 数量 | ~1,500 个 |
| 人均日产出 | 3.5 个 PR |
| 开发效率 | 手写代码的 1/10 |
| 用户验证 | 数百名内部用户实际使用 |
工程师不再写代码。他们的工作变成了:
- 设计环境:为 Agent 创建可操作的工作空间
- 指定意图:通过 prompt 描述任务
- 构建反馈循环:让 Codex 能可靠地完成工作
- 深度优先分解:将大目标拆解为小的构建块
当 Agent 失败时,修复方式不是 “try harder”,而是问:”缺什么能力?如何让它对 Agent 既可读又可执行?”
OpenAI 总结了 Harness 的五大原则:
1. 仓库知识作为系统记录。 AGENTS.md 约 100 行,作为”目录”而非”百科全书”。知识库存放在结构化的 docs/ 目录中,实现渐进式披露。
2. Agent 可读性优先。 对 Agent 不可见的知识等于不存在。Slack 讨论、Google Docs 中的决策必须编码进仓库。偏好”无聊”技术——组合性好、API 稳定、训练集中有表示的技术。
3. “Enforce invariants, not micromanaging implementations.”(通过不变量约束,而非微管理实现。) 打个比方:你不需要告诉 Agent “这个函数只能有 15 行””变量名必须用驼峰”——那是微管理。你需要的是画一条红线:代码只能从上层调用下层,绝不能反过来。具体来说,团队规定了严格的分层顺序:Types → Config → Repo → Service → Runtime → UI,低层不能反向依赖高层,跨层调用必须走一个统一的接口(Providers)。这些规则不是写在文档里靠人遵守,而是写成自动检查工具(Linter)——Agent 写的代码只要违规,机器直接拦住。”The constraints are what allows speed without decay or architectural drift.”(正是这些约束,让速度不会伴随着衰减或架构漂移。)更聪明的是,Linter 的报错不只是冷冰冰地报”违规了”,而是会告诉 Agent:”你错在哪、为什么错、怎么改”——原文叫 “inject remediation instructions into agent context”(向 Agent 的上下文注入修复指令)。这样一来,Agent 看到报错就能自己修正,不需要等人类来审。
4. “Corrections are cheap, and waiting is expensive.”(修正成本低,等待成本高。) 在人均每天 3.5 个 PR 的高吞吐量环境下,团队的合并哲学是:”Pull requests are short-lived. Test flakes are often addressed with follow-up runs.”(PR 短生命周期,测试 flake 用后续运行解决,不阻塞进度。)他们也坦承:”This would be irresponsible in a low-throughput environment.”(如果吞吐量低,这种做法是不负责任的。)——言下之意,只有当 Agent 能快速修正时,”先合并再修”才成立。
5. 熵与垃圾收集。 后台 Codex 任务定期扫描代码漂移,更新质量评级,发起重构 PR。大多数重构 PR 可在不到一分钟内审查并自动合并。
Birgitta Böckeler 的系统化框架
2026 年 4 月,Thoughtworks 杰出工程师 Birgitta Böckeler 在 Martin Fowler 的网站上发表了《Harness Engineering for Coding Agent Users》,将这个实践概念提升为一个完整的思维模型。Martin Fowler 本人称之为 “superb article”(一篇出色的文章)。
核心公式
Agent = Model + Harness
Harness 是 Agent 中除模型之外的一切。它分为三层同心圆:
- 核心:模型(被驾驭的对象)
- 中间层:Agent 平台自带的 builder harness(系统提示、代码检索机制、编排系统)
- 外层:用户在自己项目上构建的 user harness
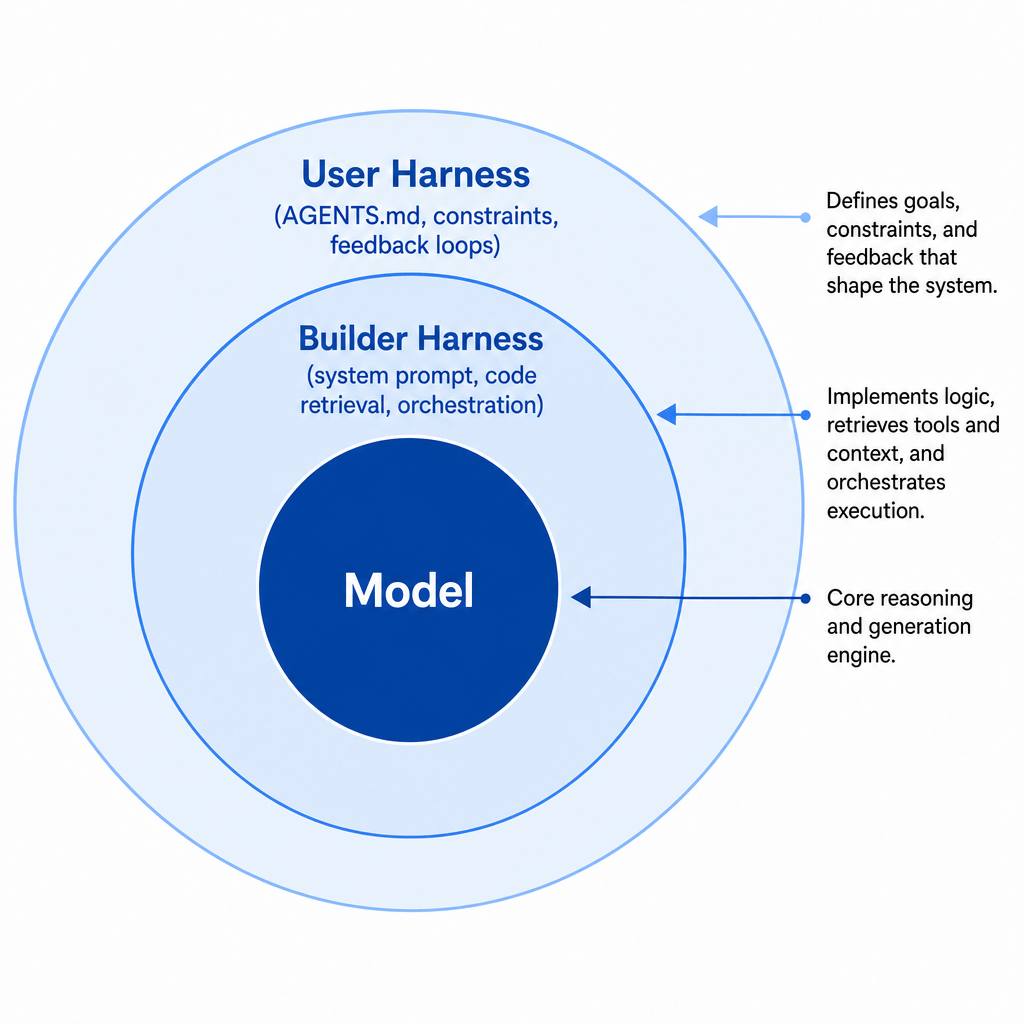
构建 user harness 的两个目标:
- 最大化 Agent 首次成功的概率
- 创建自纠正反馈循环,减少人工审查负担
两大控制机制
Guides(前馈控制)——在 Agent 行动之前引导,提高首次成功率。
例子:AGENTS.md 文件、Skills、架构文档、代码修改工具。
Sensors(反馈控制)——在 Agent 行动之后观察结果并帮助其自纠正。
特别强大的是:为 LLM 消费优化的信号。比如自定义 Linter 的报错信息,不只说”你违反了规则 X”,还包含自纠正指令——Böckeler 称之为 “a positive kind of prompt injection”(一种积极的提示注入)。
两者必须协同工作:只有反馈的 Agent 会重复犯错;只有前馈的 Agent 编码了规则但从不验证是否有效。
两种执行类型
| 类型 | 特点 | 例子 |
|---|---|---|
| 计算型 | 确定性、CPU、快速、可靠 | 测试、Linter、类型检查、结构分析 |
| 推理型 | 语义分析、GPU、慢、贵、非确定性 | AI 代码审查、”LLM as judge” |
计算型传感器跑在毫秒到秒级,结果可靠。推理型传感器允许更丰富的语义判断,但更慢、更贵、结果不确定。两者互补:计算型提供确定性底线,推理型处理计算型无法覆盖的语义问题。
三大调节维度
| 维度 | 难度 | 现状 |
|---|---|---|
| 可维护性 Harness | 最容易 | 大量现有工具(重复代码检测、复杂度分析、覆盖率检查) |
| 架构适应度 Harness | 中等 | 本质是 Fitness Functions——定义和检查架构特征的引导和传感器 |
| 行为 Harness | 最难 | “房间里的大象”——功能正确性。AI 生成的测试还远远不够好 |
行为 Harness 是目前最大的开放问题。当前做法依赖 AI 生成的测试套件,但 Böckeler 警告:”This approach puts a lot of faith into the AI-generated tests, that’s not good enough yet.”(这种方法过于信任 AI 生成的测试,目前还远远不够。)
与传统软件工程的关系
Böckeler 文章最独特的贡献,是将 Harness 工程牢固地植根于已有的软件工程实践:
- CI/CD:将检查尽可能左移(shift-left)
- Fitness Functions:架构适应度 harness 本质上就是 fitness functions 的应用
- 控制论(Cybernetics):harness 被定位为一种 cybernetic governor,调节代码库向期望状态靠拢
- Ashby 必要多样性定律:约束器必须至少具有与其所约束系统一样多的多样性。LLM Agent 能产生几乎任何东西,但承诺一种拓扑结构可以缩小空间,使全面约束变得可行
核心洞察:Harness 工程不是凭空出现的新概念,而是这些传统实践在 AI 增强开发世界的自然演进。
LangChain 的实战验证
如果说 OpenAI 的数据展示了 Harness 工程的潜力,LangChain 的实验则精确地量化了它的效果。
LangChain 在 Terminal Bench 2.0(89 个跨 ML、调试、生物等领域的任务)上做了一组对照实验。模型固定为 GPT-5.2-Codex,零改动,只改 Harness:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 得分 | 52.8% | 66.5% |
| 排名 | 第 30 名 | 第 5 名 |
他们调整了三个 Harness 旋钮:
System Prompt 优化——设计了 4 步问题解决引导:规划与发现 → 构建 → 验证 → 修复。核心改变是解决了 Agent 最常见的问题模式:写完代码后自己读一遍,确认”看起来没问题”,然后就停了——从没真正运行过测试。
Middleware 优化——
PreCompletionChecklistMiddleware:在 Agent 准备退出时拦截,提醒它对任务规格做一次验证检查LoopDetectionMiddleware:追踪每个文件的编辑次数,超过 N 次后提醒”考虑换个方法”,打破 doom loopsLocalContextMiddleware:Agent 启动时注入目录结构和可用工具信息,减少错误面
推理预算优化——GPT-5.2-Codex 有 4 档推理模式。他们发现只用最高档(xhigh)反而得分低(53.9%),因为 Agent 经常超时。最终方案是 “Reasoning Sandwich”(推理三明治):规划阶段用 xhigh,实现阶段用 high,验证阶段再用 xhigh。这一招把得分从 63.6% 推到了 66.5%。
LangChain 总结了五条通用原则:
- 为 Agent 做上下文工程:注入目录结构、可用工具、编码规范、问题解决策略
- 帮 Agent 自我验证:强制要求运行测试和对照任务规格
- Trace 作为反馈信号:调试工具和推理过程结合,让 Agent 能自我评估
- 短期检测和修复坏模式:循环检测和验证清单即使模型进步后仍然有用
- 按模型定制 Harness:不同模型需要不同的提示策略
Harness 在技术栈中的位置
Harness 不是要替代现有的 SDK、脚手架或 Agent 框架,而是在它们之上增加一个额外层:
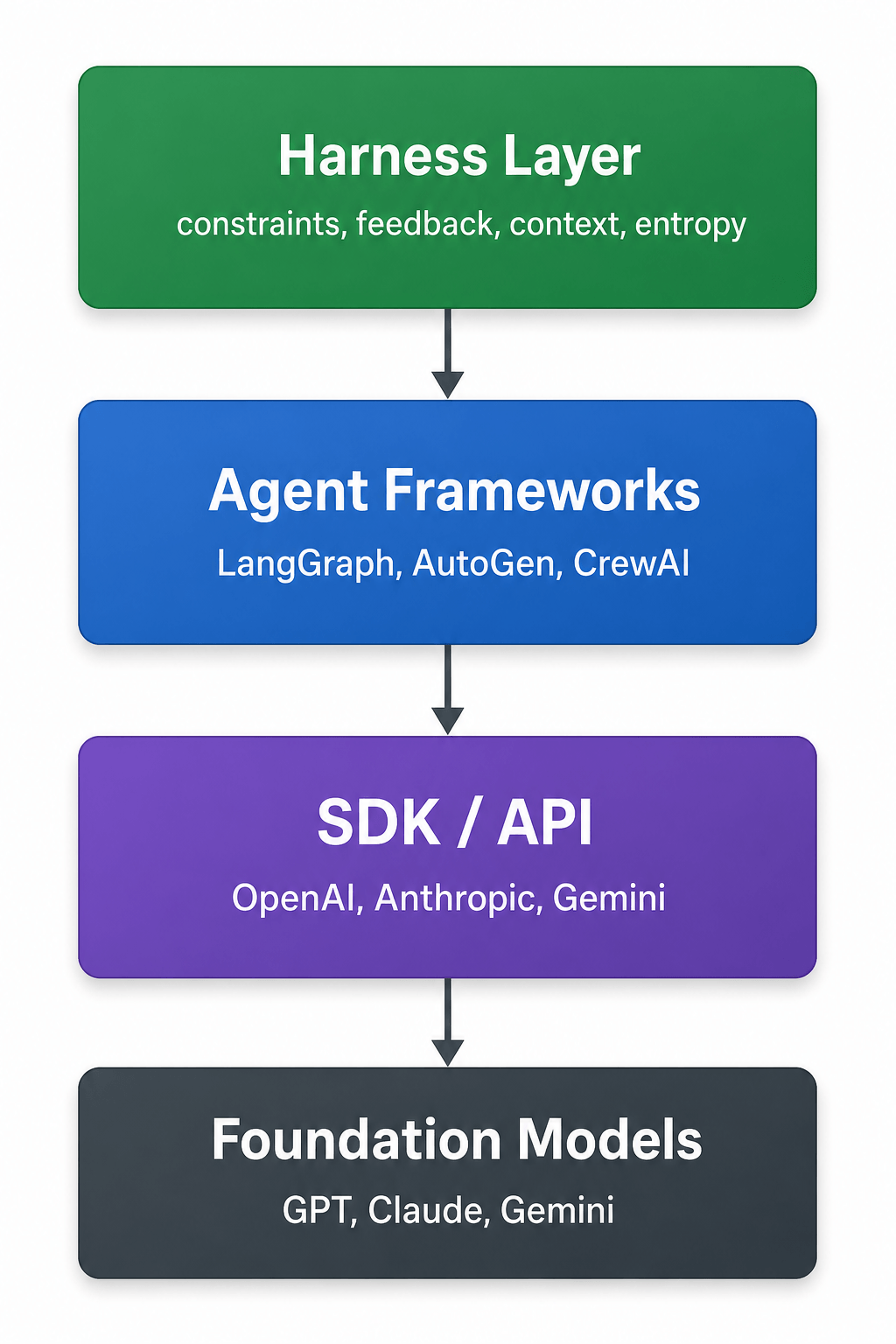
1 | |
传统框架解决如何构建 AI Agent。Harness 层解决一个根本不同的问题:如何让 Agent 可靠地运行。
模型正在逐步吸收约 80% 的框架功能,但剩下的 20%——持久化、确定性回放、成本控制、可观测性、错误恢复——正是 Harness 层提供价值的地方。
工程师角色的转变
Harness 工程带来的最深层变化,是工程师角色的重新定义。
过去,工程师的核心工作是写代码。现在,工程师的核心工作变成了设计 Agent 运行的环境。用 Böckeler 的话说,人类开发者带来的”隐式 harness”包括:
- 内化的编码规范和最佳实践
- 对复杂性之痛的身体感知
- 社会责任感(commit 上有你的名字)
- 组织认同——知道团队目标、可接受的技术债、”好”的具体含义
而 Agent 缺乏这些。它没有社会责任感,不会对 300 行的函数产生”审美厌恶”,不会直觉地觉得”我们这里不这么做”,没有组织记忆,不知道哪些约定是承重的、哪些只是习惯。
Harness 工程试图将人类开发者的经验外化为可执行的约束。但它只能走到一定程度。Böckeler 的结论是:
“A good harness should not necessarily aim to fully eliminate human input, but to direct it to where our input is most important.”
好的 Harness 不一定要完全消除人类参与,而是要把人类的注意力引导到最需要的地方。
开放问题
Harness 工程作为一个新兴实践,还有许多未解之题:
- Harness 规模增长后如何保持一致性? 指令和反馈信号越来越多,如何避免矛盾?
- 当指令和反馈冲突时,Agent 能否被信任做出合理权衡?
- 传感器从未触发,代表高质量还是检测不足? 需要类似代码覆盖率的 “harness coverage” 指标。
- 分散的控制如何统一管理? 前馈和反馈控制散布在交付流程的各个阶段,需要能配置、同步和推理它们的工具。
- “Apprentice Gap” 问题——如果我们太早让初级开发者脱离”环内”,可能导致未来没有人足够深入理解”怎么做”来构建健壮的 Harness。
给工程师的行动指南
如果你现在就想开始实践 Harness 工程,这里是按优先级排列的行动清单:
第一步:创建 AGENTS.md。 不要写成百科全书。像 Hashimoto 那样,每一行都对应一个 Agent 犯过的错误。从空白开始,每次 Agent 犯错就加一行。
第二步:给 Agent 验证手段。 测试套件、截图工具、Linter。让 Agent 能自己告诉自己”我做对了”。这是最高杠杆的单一改进。
第三步:设计 Linter 报错信息。 不要只写”违反规则 X”。写”违反规则 X,因为 Y,正确做法是 Z”。这是成本最低的”积极提示注入”。
第四步:建立增量工作流。 每次会话只做一个功能。用 git commit + 进度文件做状态交接。不要让 Agent 在一个会话里做所有事。
第五步:定期清理熵。 后台跑 Agent 扫描代码漂移,提交重构 PR。技术债是高利贷,越早还越便宜。
结语

Harness 工程的本质,是一句简单但深刻的话:
与其换一匹更强的马,不如修一条更好的路。
模型会继续变强,但模型变强不会让 Harness 变得不重要——恰恰相反。更强的模型意味着更大的能力空间,也就需要更精细的约束来保证可靠性。正如 Böckeler 所引用的:
To achieve higher AI autonomy, runtime constraints must be stricter. Building trust requires more constraints, not more freedom — like highway guardrails that let you safely drive at 120 km/h.
要实现更高程度的 AI 自主性,运行时约束必须更严格。建立信任需要更多约束,而非更多自由——就像高速公路护栏让你能安全地以 120 km/h 的速度行驶。
工程师的价值正在从执行者转变为赋能者和系统思维者——从构建产品,到构建能构建产品的工厂。
这或许就是 AI 时代软件工程最核心的范式转变。
参考来源:
- Mitchell Hashimoto, My AI Adoption Journey, 2026-02-05
- Ryan Lopopolo, Harness engineering: leveraging Codex in an agent-first world, 2026-02-11
- Birgitta Böckeler, Harness Engineering for Coding Agent Users, 2026-04-02
- Justin Young, Effective harnesses for long-running agents, 2025-11-26
- Anthropic, Effective context engineering for AI agents, 2025-09-29
- Viv Trivedy, LangChain Terminal Bench optimization