语言模型的演进:从n-gram到GPT-4
语言模型的演进:从n-gram到GPT-4
引言
2022年11月30日,OpenAI的网站因为流量过大而反复宕机。五天内,ChatGPT的用户突破一百万;两个月后,这个数字超过了1亿。一个AI聊天产品以人类历史上最快的速度完成了用户增长,背后的推动力只有一个:它真的能”说话”。
但ChatGPT并非从天而降。1948年,克劳德·香农在《通信的数学理论》中提出了信息熵的概念,并做了一个有趣的实验:给人看一段英文文本的前几个字母,让他们猜测下一个字母是什么。这个看似游戏的实验,揭示了一个深刻的事实——语言是有结构的,而这种结构可以被数学建模。”预测下一个符号”,正是语言模型最原始的思想源头。
从香农的纸笔实验,到1990年代统计学家用计数表估算词频,到2013年神经网络学会把词变成向量,到2018年BERT和GPT用海量文本预训练通用语言知识,再到2020年GPT-3用1750亿参数证明”规模本身就是一种能力”——每一代研究者都在追问同一个问题:如何让机器更准确地预测下一个词?
这个问题的答案,最终催生了我们今天所见的AI革命。
理解这条从n-gram到GPT-4的演进脉络,不是回顾技术史的学术练习,而是回答一个当下最紧迫的问题:这些系统到底是怎么工作的?它们为什么突然变得如此强大?
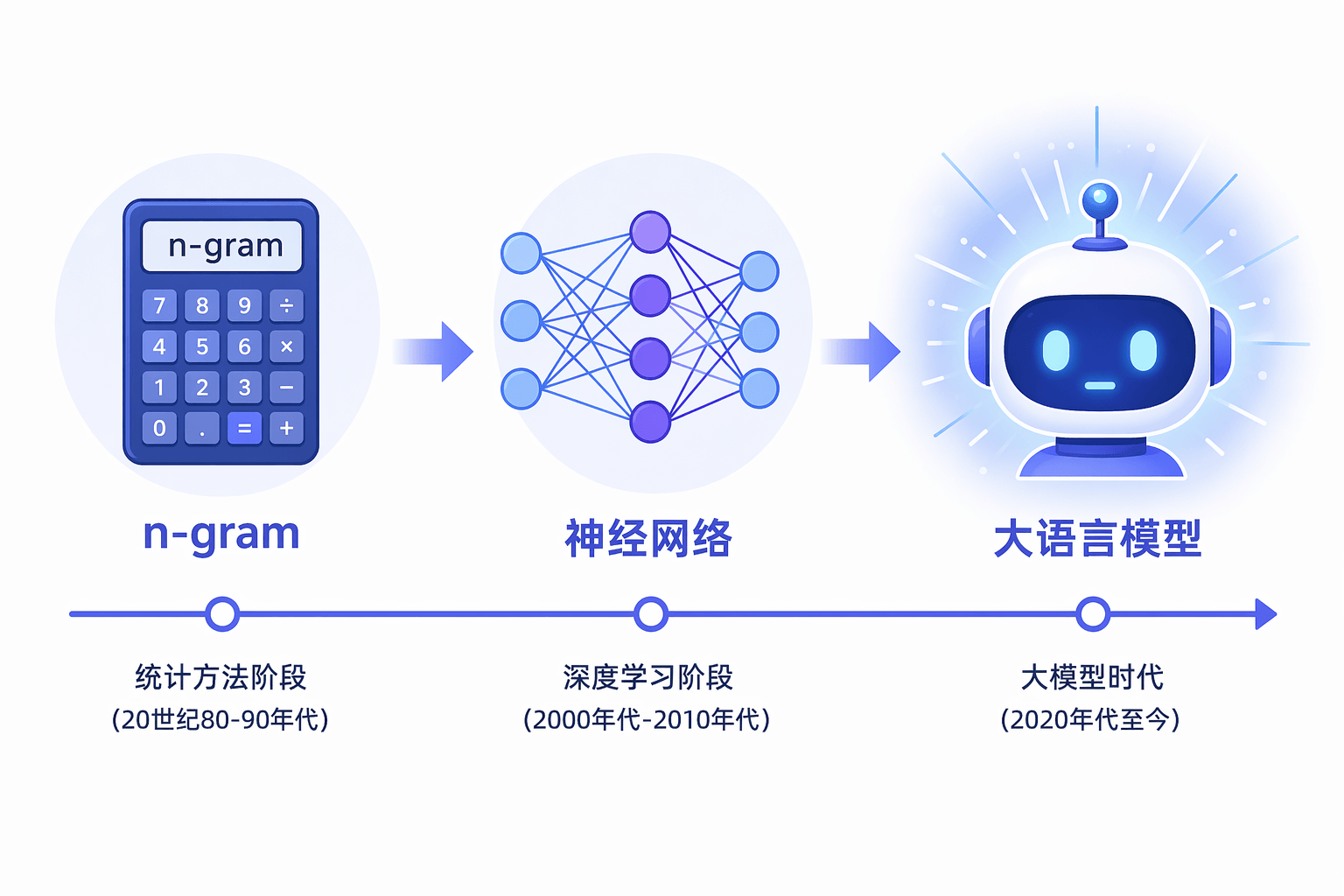
第一幕:统计语言模型(1990s)
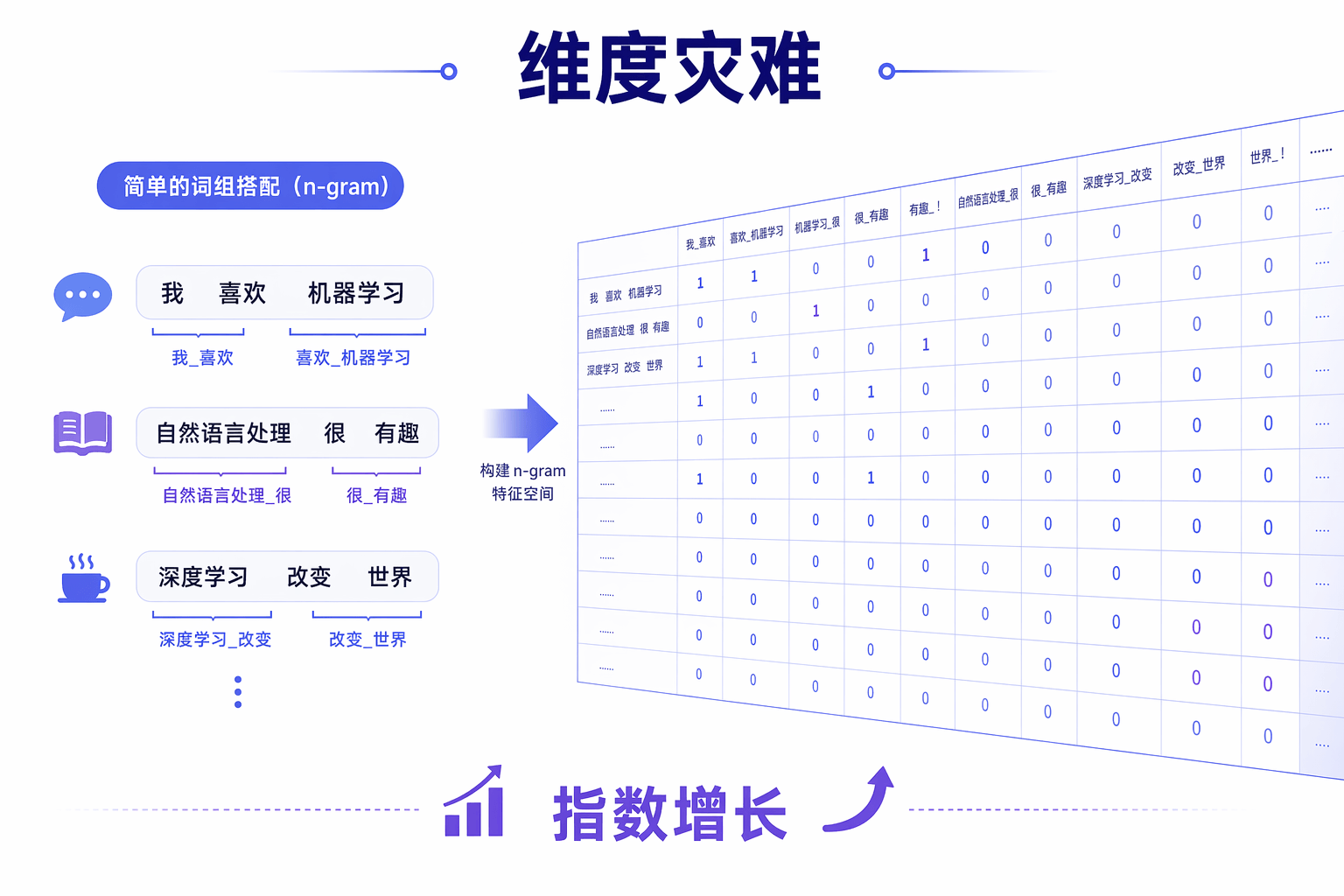
最早的语言模型基于一个直觉:一个词出现的概率,取决于它前面出现的几个词。这就是n-gram模型的核心思想——用马尔可夫假设简化概率计算。
例如,一个三元组(trigram)模型预测”P(今天|我, 去)”时,只需要统计语料库中”我 去 今天”出现的频率,除以”我 去”出现的总次数。简单、直观、有效。
但n-gram有一个致命缺陷:维度灾难。当n增大时,可能的词组合呈指数级增长,而语料库中的统计数据远远不够。一个四元组模型需要存储的参数量可以达到数万亿,这在当时几乎无法处理。为缓解数据稀疏问题,研究者发明了各种平滑策略(如回退估计、Good-Turing估计),但本质上都是在有限数据下的权宜之计。
统计语言模型的贡献在于确立了一个关键范式:语言建模本质上是一个概率估计问题。它的局限则在于:以词为单位的离散表示,无法捕捉语义的相似性——“猫”和”狗”在向量空间中的距离,与”猫”和”桌子”一样远。
第二幕:神经语言模型(2013-2017)
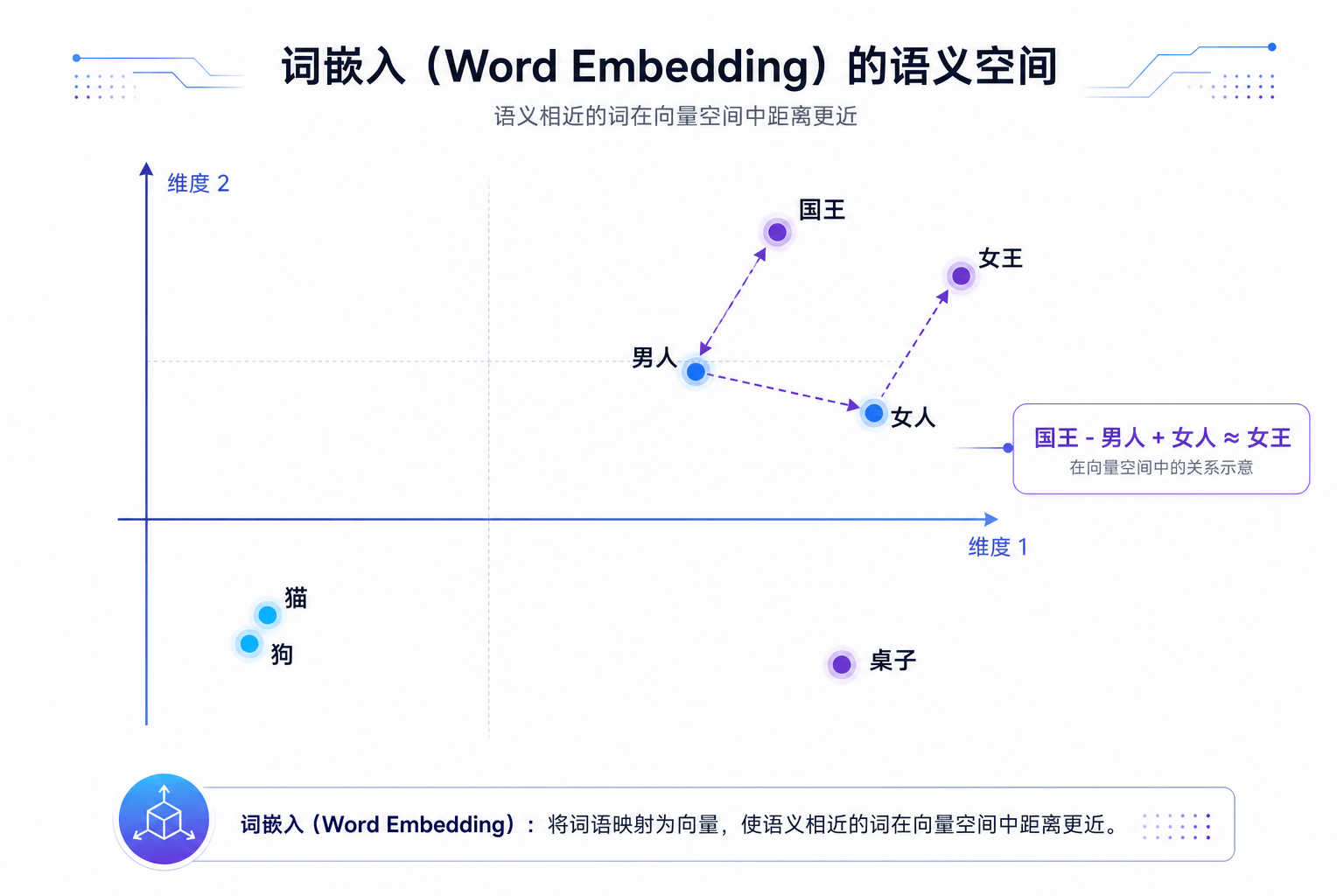
2013年,Google的Tomas Mikolov提出了Word2Vec。它用一个浅层神经网络将每个词映射为一个稠密的低维向量(词嵌入),使得语义相近的词在向量空间中距离也相近。”国王” - “男人” + “女人” ≈ “女王”——这个经典的类比关系,证明了神经网络可以学习到有意义的语义表示。
随后,研究者开始用循环神经网络(RNN)及其变体LSTM来建模序列。与n-gram的固定窗口不同,RNN理论上可以捕捉任意长度的上下文依赖。LSTM通过门控机制缓解了梯度消失问题,在机器翻译、文本生成等任务上取得了显著进步。
这一阶段的核心贡献是表示学习:从人工设计特征转向让模型自动学习特征。但它也面临一个根本性矛盾——RNN的顺序计算特性使其难以并行化,训练效率低下;同时,随着序列变长,早期的信息会被逐渐稀释,长距离依赖仍然难以捕捉。
第三幕:预训练语言模型(2018-2020)
2017年,Google发表了”Attention Is All You Need”,提出了Transformer架构。这个架构用自注意力机制(self-attention)完全替代了循环和卷积,使得模型可以并行计算序列中任意两个位置之间的关系。多头注意力(multi-head attention)让模型可以同时关注不同层面的语义信息,位置编码(positional encoding)则弥补了注意力机制本身对位置不敏感的缺陷。
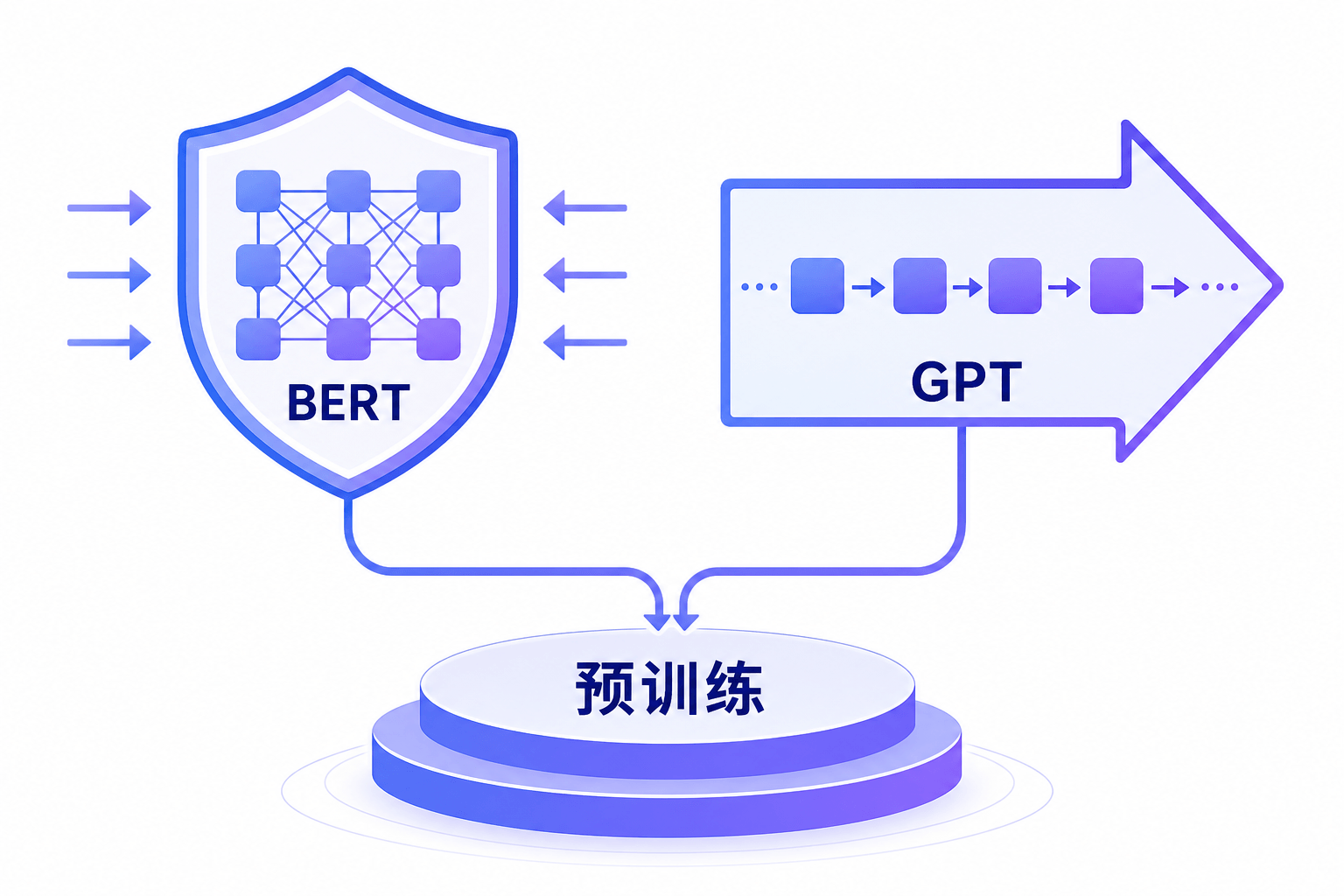
Transformer最初用于机器翻译(编码器-解码器结构),但很快被拆解为两种范式:
BERT(2018) 采用编码器路线。Google的Jacob Devlin等人提出了”掩码语言模型”(MLM)预训练任务:随机遮住句子中的一些词,让模型根据上下文预测被遮住的词。这种双向注意力机制让BERT能够同时利用左右两侧的上下文信息。配合”下一句预测”(NSP)任务,BERT在11项NLP基准上刷新了记录。”预训练+微调”(pre-train + fine-tune)的范式由此确立:先在大规模无标注语料上预训练通用语言表示,再用少量标注数据微调到具体任务。
GPT-1(2018) 采用解码器路线。OpenAI的Alec Radford等人用Transformer解码器在BooksCorpus上进行自回归语言建模预训练,然后在下游任务上微调。GPT-1的规模(1.17亿参数)在当时并不算大,但它确立了一个核心原则:用语言建模来压缩世界知识。
GPT-2(2019) 将参数扩展到15亿,用更大的网页数据集WebText训练。GPT-2提出了一个大胆的主张:足够大的语言模型无需微调就能执行多种任务。它引入了一个概率框架:p(output | input, task)——将任务、输入、输出统一编码为文本序列,通过语言建模来求解任务。OpenAI因担心滥用而一度限制发布,这本身也说明了模型能力的惊人程度。
预训练语言模型的革命在于:用无监督学习从海量文本中提取通用知识,再通过少量监督信号适配到具体任务。这个范式极大地降低了NLP对标注数据的依赖。
第四幕:大语言模型的崛起(2020-2022)
GPT-3:规模的力量
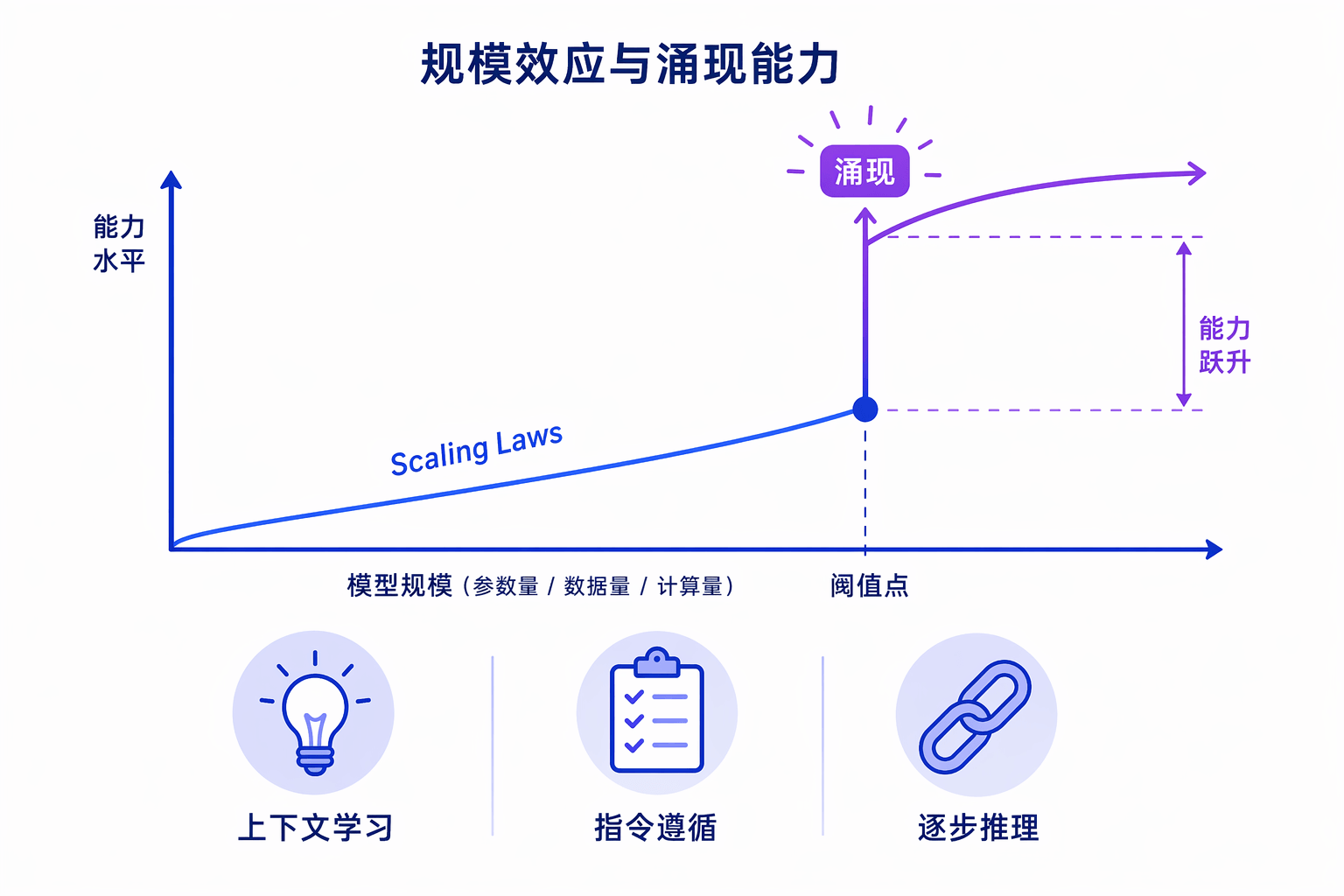
2020年,OpenAI发布了GPT-3,将参数量推到了1750亿。GPT-3真正引人注目的不是规模本身,而是它展现出的涌现能力(emergent abilities):小模型不具备、只有当规模超过某个阈值后才会突然出现的能力。
最典型的涌现能力是上下文学习(in-context learning, ICL)。GPT-3可以在不进行任何梯度更新的情况下,仅通过在输入中提供几个示例(few-shot),就能完成翻译、问答、推理等任务。这意味着预训练和使用收敛到了同一个范式:预训练预测后续文本序列,ICL则预测给定任务描述和示例后的正确答案。
GPT-3的论文没有明确讨论涌现能力,但从实验结果可以清楚地看到:更大规模的模型展现出远超小模型的ICL能力。这种能力的突然出现,类似于物理学中的相变——量变积累到临界点,质变突然发生。
Scaling Laws:规模的数学
GPT-3的成功并非偶然。2020年,OpenAI的Jared Kaplan等人发表了”Scaling Laws for Neural Language Models”,揭示了一个深刻的规律:模型性能(以交叉熵损失衡量)与参数量、数据量、计算量之间存在幂律关系。
L(N) = (N_c / N) ^ α_N, 其中 α_N ≈ 0.076
L(D) = (D_c / D) ^ α_D, 其中 α_D ≈ 0.095
L(C) = (C_c / C) ^ α_C, 其中 α_C ≈ 0.050
这意味着:给定计算预算,模型性能的提升是可以预测的。这个发现有两个重要启示:第一,可以通过小模型的实验来预测大模型的表现;第二,单纯增加模型规模会带来收益递减——性能提升越来越慢。
Chinchilla:计算最优训练
2022年,DeepMind的Jordan Hoffmann等人提出了另一种缩放定律的形式:
L(N, D) = E + A·N^α + B·D^β
其中 E = 1.69,A = 406.4,B = 410.7,α = 0.34,β = 0.28。
Chinchilla的关键洞察是:在固定计算预算下,参数量和训练数据量应该等比缩放。此前的大模型(如2800亿参数的Gopher)严重”欠训练”——模型很大但训练数据不够。Chinchilla用700亿参数、1.4万亿token训练,性能反而超越了参数量是其4倍的Gopher。
这个发现改变了整个行业的训练策略。LLaMA系列就是Chinchilla思想的直接产物:用更小的模型、更多的数据、更长的训练时间,达到甚至超越更大模型的性能。
涌现能力的三种形态
涌现能力在大语言模型中有三种典型表现:
上下文学习(ICL):GPT-3首次正式提出。模型通过输入中的自然语言指令和示例来理解任务,无需微调。
指令遵循:通过对多任务数据集进行指令微调(instruction tuning),LLM可以理解并执行自然语言描述的任务。实验表明,指令微调后的LaMDA-PT在模型规模达到680亿参数时,才开始显著超越未微调版本。
逐步推理:通过链式思维(Chain-of-Thought, CoT)提示,LLM可以在回答问题时展示中间推理步骤。CoT提示在模型规模超过600亿参数时开始产生收益,超过1000亿参数时优势更加明显。
这三种能力都有一个共同特点:它们不是渐进式提升,而是在某个规模阈值后突然出现。这与Scaling Laws描述的平滑提升形成了有趣的对比——Scaling Laws描述的是可预测的、连续的性能提升;涌现能力描述的是不可预测的、跳跃式的能力涌现。
对齐:让模型与人类价值观一致(2022-2023)
大语言模型的预训练目标是”预测下一个词”,这并不等同于”生成有用、无害的回答”。预训练语料中包含大量低质量、有害、偏见的内容,模型会忠实地学习这些模式。对齐(alignment)就是要弥合”模型能做什么”和”人类希望它做什么”之间的鸿沟。
RLHF:三步法
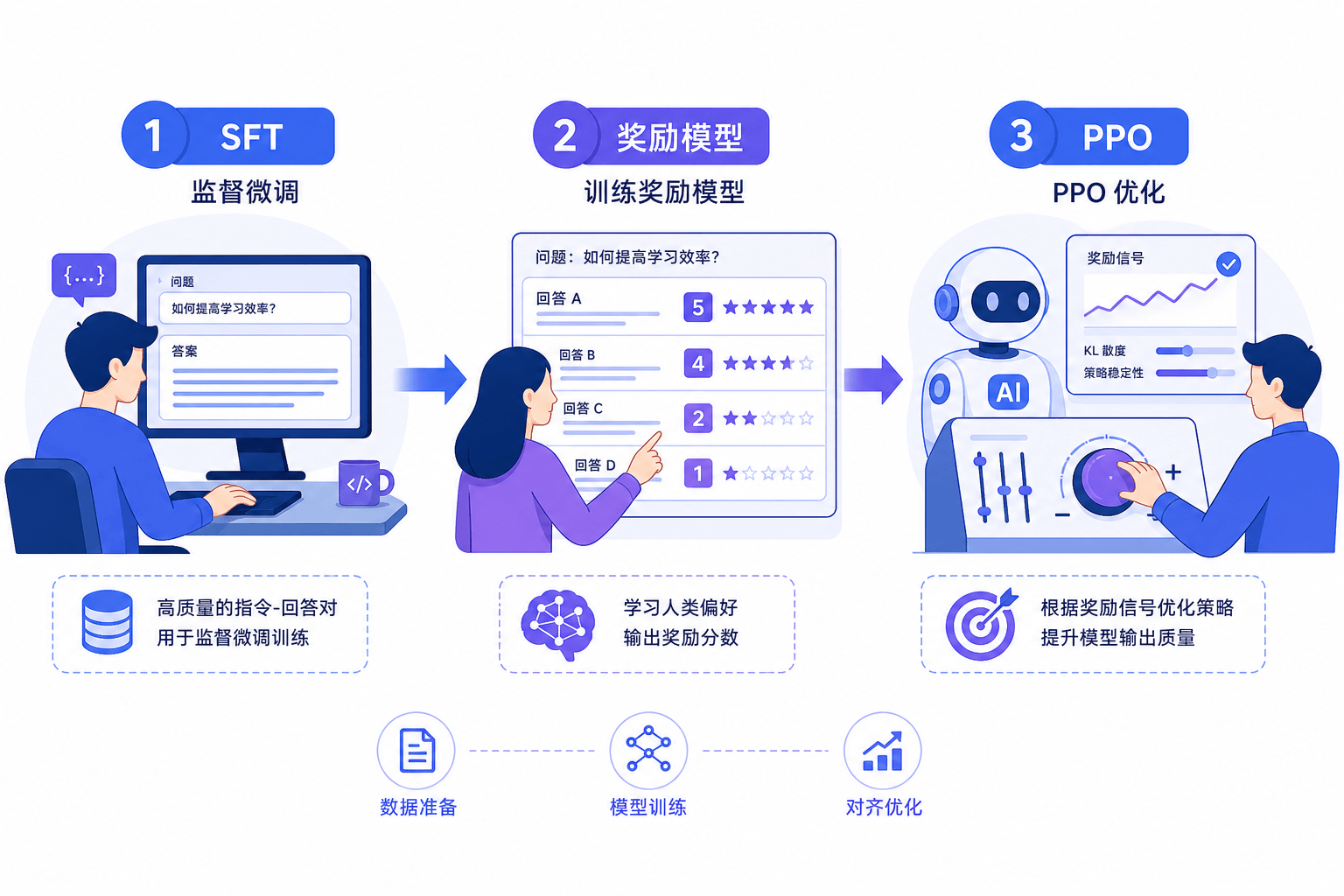
OpenAI在InstructGPT(2022)中确立了RLHF(Reinforcement Learning from Human Feedback)的标准流程:
第一步:监督微调(SFT)。收集人类标注者编写的高质量回答,对预训练模型进行微调。这一步让模型学会”按照指令回答问题”的基本模式。
第二步:训练奖励模型(Reward Model)。给定同一个提示,让SFT模型生成多个回答,人类标注者对这些回答进行排序。用这些排序数据训练一个奖励模型,使其能够预测人类对回答的偏好分数。
第三步:PPO优化。用奖励模型的分数作为奖励信号,通过近端策略优化(PPO)算法进一步微调语言模型。同时加入KL散度约束,防止模型偏离预训练分布太远。
InstructGPT的结果说明了一个重要事实:一个经过RLHF对齐的13亿参数模型,在人类评估中优于未经对齐的1750亿参数GPT-3。对齐不仅仅是安全措施,更是能力提升手段。
DPO:简化RLHF
2023年,斯坦福的Rafael Rafailov等人提出了DPO(Direct Preference Optimization),用一个精巧的数学变换证明了:语言模型本身就可以看作一个隐式的奖励模型。这意味着可以跳过训练单独奖励模型的步骤,直接用偏好数据优化语言模型,效果与PPO方法相当。
DPO的核心思想是:用闭式解替代复杂的强化学习训练管线,大大降低了对齐的技术门槛和计算成本。
Constitutional AI:AI自我反馈
Anthropic在Constitutional AI中提出了另一种思路:用AI自我反馈(RLAIF)替代人类标注。具体做法是:给模型一组”宪法原则”(如”回答应当有帮助”、”回答不应包含有害内容”),让模型根据这些原则自我批评和修正回答,然后用修正后的数据进行训练。
这种方法的优势在于:减少了对人类标注的依赖,同时可以更系统地定义和执行对齐标准。
ChatGPT:对齐的集大成者
2022年11月,OpenAI发布了ChatGPT。它基于GPT-3.5(经过代码训练的改进版GPT-3),采用了类似InstructGPT的RLHF训练方法,专门针对对话场景进行了优化。ChatGPT在人类对话中展现出的知识储备、数学推理、多轮上下文追踪和价值观对齐能力,让它成为AI历史上最轰动的产品发布。
ChatGPT的成功表明:对齐不是锦上添花,而是将大语言模型从实验室推向数亿用户的关键一步。
开源运动:民主化大语言模型(2023-至今)
2023年2月,Meta发布了LLaMA系列,这成为大语言模型领域的标志性事件。
LLaMA的核心主张是:在公开数据上训练的模型,可以匹配甚至超越闭源模型。LLaMA(7B-65B参数)用1.4万亿token训练,性能与GPT-3(1750亿参数)相当,但参数量小了一个数量级。这直接验证了Chinchilla的计算最优训练策略——更小的模型配上更多的数据和更长的训练时间,可以达到更好的效果。
LLaMA 2(2023年7月)进一步扩展到7B/13B/70B参数,使用2万亿token训练,并经过RLHF微调。它开放了模型权重供研究和商用,这在闭源模型主导的格局中具有里程碑意义。
开源模型的兴起产生了深远影响:
- 研究民主化:研究者无需巨额计算资源就可以在强大模型上进行实验
- 社区创新:基于LLaMA的微调模型(如Alpaca、Vicuna)在短时间内大量涌现
- 安全研究:开放权重使得对齐、鲁棒性等安全研究可以在真实模型上进行
- 竞争格局:开源模型与闭源模型形成了健康的竞争关系
LLaMA之后,Mistral(法国)、Qwen(阿里)、GLM(清华)、DeepSeek(深度求索)等开源模型相继涌现,形成了百花齐放的局面。特别是DeepSeek-V3和DeepSeek-R1,证明了开源模型在推理能力上也能达到顶尖水平。
结语:下一步是什么
回顾语言模型的三十年演进,有一条清晰的主线:从辅助特定任务的工具,到通用的任务求解器。
统计语言模型为语音识别和信息检索提供概率支持;神经语言模型学会了自动提取语义特征;预训练语言模型通过大规模自监督学习获取通用语言知识;大语言模型则通过规模效应涌现出上下文学习、指令遵循和逐步推理等通用能力。
对齐技术让这些能力变得安全可用,开源运动让这些能力惠及整个社区。
但语言模型的演进远未结束。当前的前沿方向包括:
- 多模态:GPT-4、Gemini等模型已支持图像输入,未来的模型将进一步整合视觉、语音、视频等多种模态
- Agent能力:语言模型正在从被动回答问题的工具,演变为能够主动规划、使用工具、与环境交互的智能体
- 推理能力:从GPT-o1到DeepSeek-R1,推理时间计算(inference-time compute)正在开辟新的缩放维度
- 效率提升:混合专家模型(MoE)、量化、蒸馏等技术让强大模型的部署成本持续下降
同时,一些根本性问题仍然悬而未决:幻觉(模型生成看似合理但事实错误的内容)何时能被彻底解决?训练数据的枯竭将如何影响模型能力的持续提升?我们如何确保越来越强大的AI系统始终与人类价值观保持一致?
语言模型的故事,本质上是人类试图用数学来理解语言、进而理解智能的故事。从n-gram的计数,到Transformer的注意力,到GPT的规模效应,每一步都在回答那个古老的问题:语言的本质是什么?
而这个问题的答案,也许就藏在下一个词的概率分布里。
参考文献
- Vaswani et al., “Attention Is All You Need”, NeurIPS 2017
- Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, NAACL 2019
- Radford et al., “Improving Language Understanding by Generative Pre-Training” (GPT-1), 2018
- Radford et al., “Language Models are Unsupervised Multitask Learners” (GPT-2), 2019
- Brown et al., “Language Models are Few-Shot Learners” (GPT-3), NeurIPS 2020
- Kaplan et al., “Scaling Laws for Neural Language Models”, 2020
- Hoffmann et al., “Training Compute-Optimal Large Language Models” (Chinchilla), 2022
- Wei et al., “Emergent Abilities of Large Language Models”, 2022
- Ouyang et al., “Training Language Models to Follow Instructions with Human Feedback” (InstructGPT), NeurIPS 2022
- Rafailov et al., “Direct Preference Optimization”, 2023
- Bai et al., “Constitutional AI: Harmlessness from AI Feedback”, 2022
- Touvron et al., “LLaMA: Open and Efficient Foundation Language Models”, 2023
- Touvron et al., “LLaMA 2: Open Foundation and Fine-Tuned Chat Models”, 2023
- Zhao et al., “A Survey of Large Language Models”, 2023 (持续更新至2026)