Claude Code 缓存机制与 Token 节省完全指南
Claude Code 缓存机制与 Token 节省完全指南
用 Claude Code 写代码,最怕的不是模型笨,而是 token 消耗太快。一个复杂任务动辄几美元,如果上下文管理不好,钱花得更快。
好消息是:Claude Code 内置了自动缓存机制,但大多数人并不了解它的触发条件和优化方法。这篇文章从底层原理到实操技巧,帮你把每一分钱都花在刀刃上。
一、什么是 Prompt Caching
Prompt Caching(提示缓存)是 Anthropic 在 2024 年推出的一项功能,核心思想很简单:如果你反复发送相同的前缀内容,服务器会缓存这些内容,后续请求只需读取缓存,而不需要重新处理。
缓存的三层定价
| 类型 | 价格 | 说明 |
|---|---|---|
| 标准输入 | 正常价格 | 首次发送的 token |
| 缓存写入 | 正常价格 × 1.25 | 首次缓存时多收 25% |
| 缓存读取 | 正常价格 × 0.10 | 命中缓存时只需 10% 的费用 |
以 Claude Sonnet 4.6 为例:
| 类型 | 价格(每百万 token) |
|---|---|
| 标准输入 | $3 |
| 缓存写入 | $3.75 |
| 缓存读取 | $0.30 |
| 输出 | $15 |
也就是说,缓存命中的 token 只需正常价格的 1/10。如果你的 system prompt 有 10,000 个 token,每轮对话都命中缓存,10 轮对话下来能省下约 $2.70(相比每次都按标准价格计算)。
缓存的触发条件
缓存不是自动对所有内容生效的,它有严格的匹配规则:
- 前缀完全匹配:缓存的内容必须是请求的前缀部分,且逐字符完全一致
- 最小可缓存大小:约 1024-2048 tokens(不同模型略有差异)
- TTL(生存时间):5 分钟,每次缓存命中会刷新这个计时器
- 最多 4 个缓存断点:每个请求最多设置 4 个
cache_control标记点
简单说:你发送的内容开头必须一模一样,而且要足够长,缓存才会生效。
二、Claude Code 的缓存机制
Claude Code 作为 Agent 工具,和直接调用 API 有很大不同。它会在每次请求中自动附带大量上下文信息。
启动时自动加载的内容
每个 Claude Code 会话启动时,会自动加载以下内容到上下文窗口:
| 内容 | 大约 token 数 | 说明 |
|---|---|---|
| System prompt | ~4,200 | 核心行为指令、工具使用规则 |
| Auto memory (MEMORY.md) | ~680 | Claude 自动记录的项目知识 |
| 环境信息 | ~280 | 工作目录、平台、git 状态 |
| MCP 工具定义(延迟加载) | ~120 | 只有工具名,schema 按需加载 |
| CLAUDE.md 文件 | 变化大 | 你写的项目指令 |
关键点:这些内容在每次 API 请求中都会作为前缀发送。由于它们在会话内几乎不变,Claude Code 的自动 prompt caching 机制会缓存这些前缀,后续请求命中缓存的概率很高。
Claude Code 自动启用缓存
Claude Code 在所有部署方式下都默认启用 prompt caching:
- Anthropic API:默认启用
- Amazon Bedrock:默认启用
- Google Vertex AI:默认启用
- Microsoft Foundry:默认启用
你不需要手动设置任何 cache_control 标记,Claude Code 会自动处理。
缓存控制环境变量
如果你想精细控制缓存行为,可以使用以下环境变量:
| 环境变量 | 作用 |
|---|---|
DISABLE_PROMPT_CACHING=1 |
全局禁用缓存(优先级最高) |
DISABLE_PROMPT_CACHING_HAIKU=1 |
仅对 Haiku 模型禁用缓存 |
DISABLE_PROMPT_CACHING_SONNET=1 |
仅对 Sonnet 模型禁用缓存 |
DISABLE_PROMPT_CACHING_OPUS=1 |
仅对 Opus 模型禁用缓存 |
一般情况下不需要禁用缓存,除非你在调试特定模型或使用不兼容缓存的云提供商。
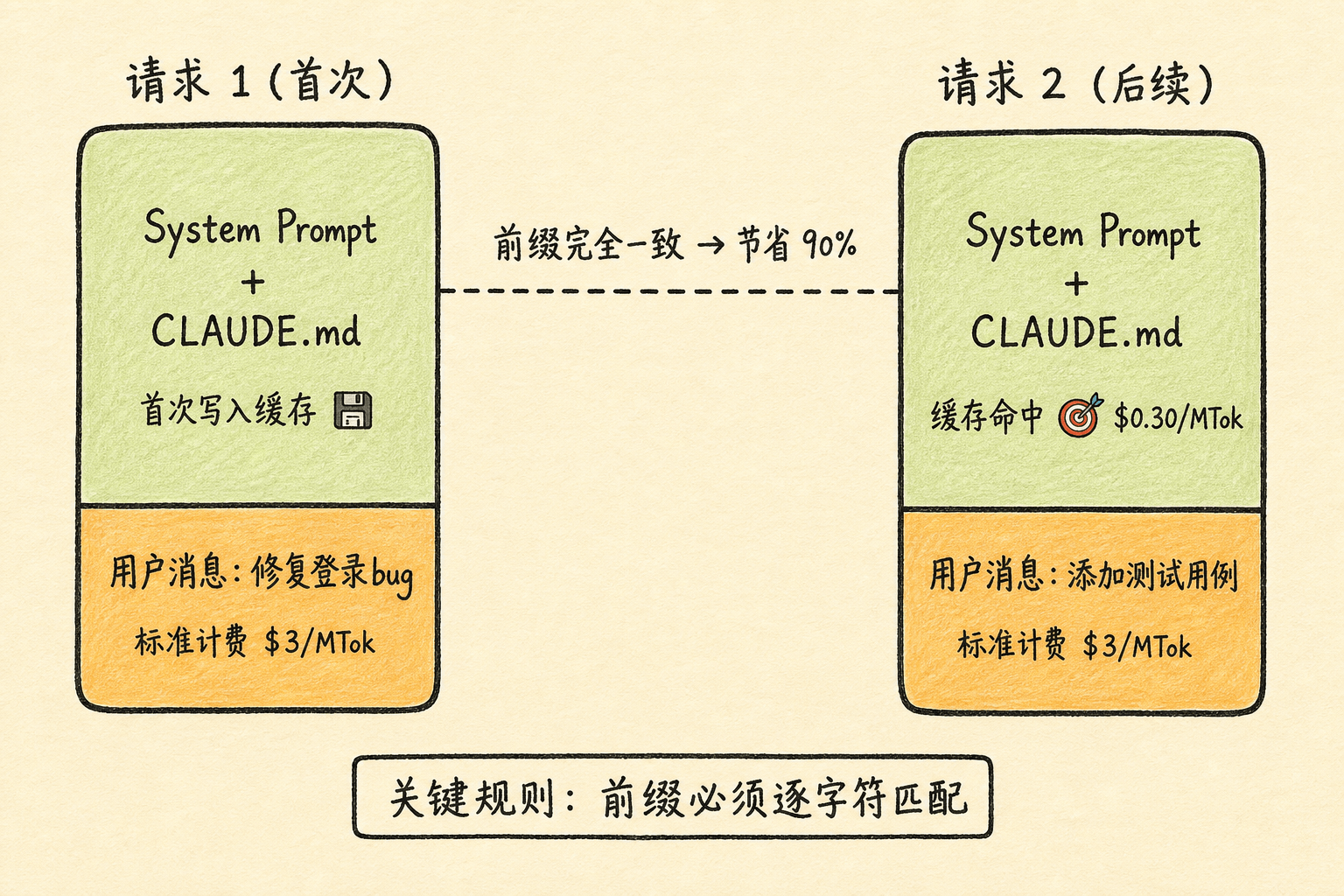
三、什么触发缓存 / 缓存命中的条件
缓存命中的核心条件:前缀匹配
缓存的工作方式是基于前缀匹配。每次 API 请求,Claude Code 会发送一个包含大量上下文的 prompt。缓存系统会检查:
- 这个 prompt 的开头部分是否和之前缓存的内容一致
- 如果一致,前面的部分按缓存读取价格计费
- 只有不一致的新增部分按标准价格计费
举个例子:
1 | 请求 1: [System Prompt + CLAUDE.md + 用户消息 "修复登录bug"] |
这两个请求的前缀 [System Prompt + CLAUDE.md] 完全一致,所以请求 2 中这部分内容会命中缓存,只有用户消息部分按标准价格计费。
什么会破坏缓存
以下情况会导致缓存失效:
- CLAUDE.md 内容变化:修改了 CLAUDE.md 文件
- auto memory 更新:Claude 在会话中写入了新的记忆
- 会话切换:不同的会话有不同的上下文
- 模型切换:用
/model切换了模型 - 工具定义变化:MCP 工具 schema 按需加载时会变化
- 超过 5 分钟未使用:TTL 过期
- cch 字段变化:详见下方
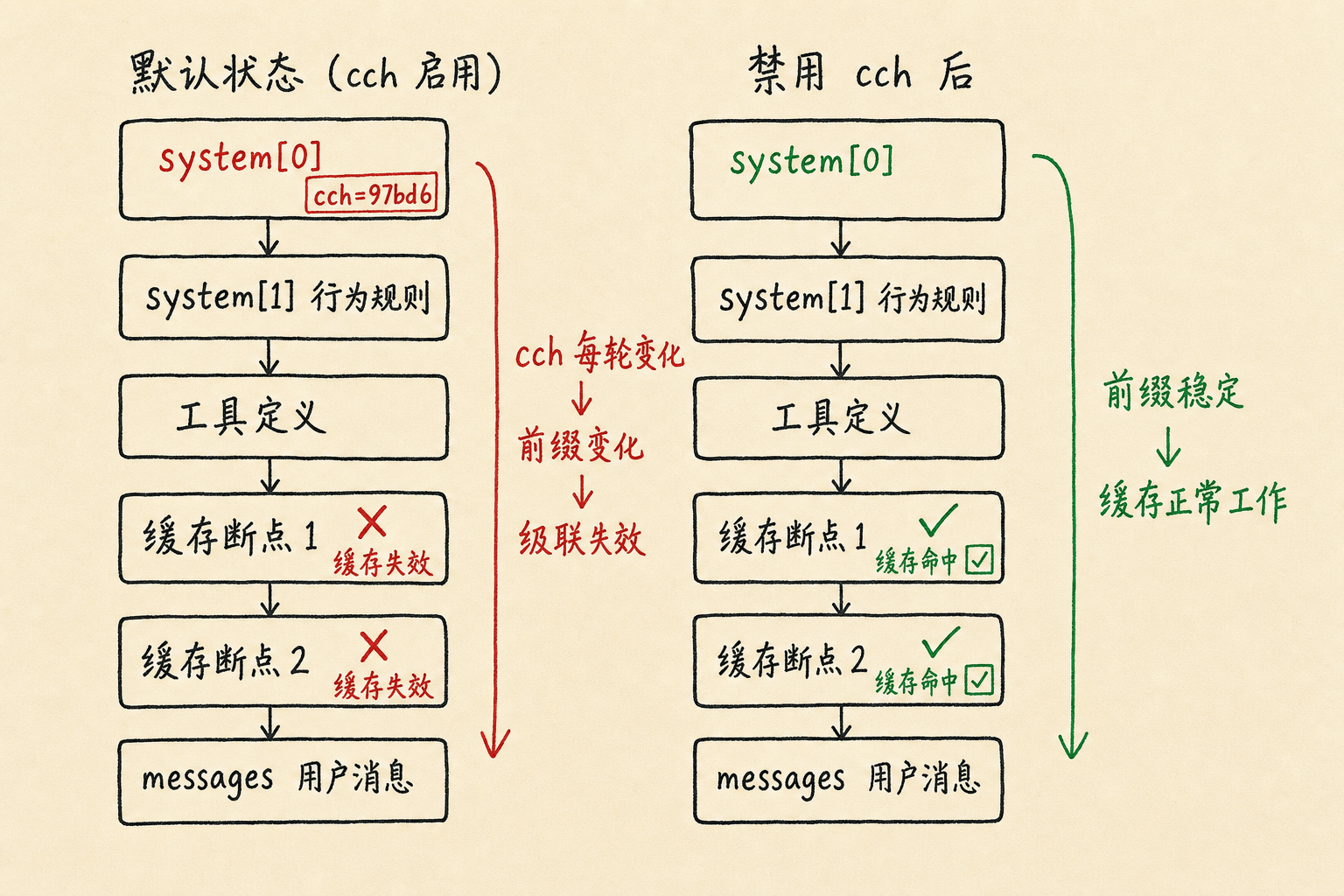
隐藏的缓存杀手:cch 字段
大多数人不知道的是,Claude Code 在每次 API 请求中都会发送一个 x-anthropic-billing-header header,其中包含一个叫 cch 的 5 位十六进制值。这个值每一轮对话都会变化。
抓包数据示例:
1 | 第 2 轮: cch=97bd6 |
这个 cch 值被嵌入在 system[0] 中——也就是 system prompt 的最前面。而 Claude Code 的缓存断点(cache breakpoints)都放在 system prompt 之后。这意味着:
1 | 请求结构: |
一个 cch 的变化,会导致级联失效——所有缓存块都被迫重新计算。
cch 的生成机制(两层架构)
cch 的生成分为两层,这种设计让外部工具无法拦截或模拟:
- JavaScript 层:在
src/constants/system.ts中,getAttributionHeader()输出一个占位符cch=00000;(5 个零匹配 5 位十六进制的长度,避免缓冲区重新分配) - Zig 原生层:Bun 的原生 HTTP 栈在
Attestation.zig中扫描发出的缓冲区,找到cch=00000;字符串,原地覆盖为真实值
由于 Zig 层运行在 JavaScript 沙箱之外,第三方代理只能看到最终结果,无法访问生成逻辑。
禁用 cch 提升缓存命中率
这是提升缓存命中率最直接有效的方法:
1 | { |
禁用后的效果:
| 状态 | system 块数 | cch 行为 | 缓存命中 |
|---|---|---|---|
| 默认(cch 启用) | 3 个 | 每轮变化 | cache_read 从未命中 |
| 禁用 cch | 2 个 | 无 | cache_read 正常命中,费用立即下降 |
禁用后,system[0] 变为身份提示(无计费 header),system[1] 为行为规则/工具描述,前缀字节在各轮之间保持一致,缓存正常工作。
缓存断点(Breakpoints)
在 API 层面,你可以通过 cache_control 标记来指定缓存断点。Claude Code 内部会自动设置这些断点,通常在:
- System prompt 之后
- 大段静态内容(如工具定义)之后
每个请求最多 4 个断点,这意味着你可以缓存最多 4 个不同的前缀段。
四、如何提高缓存命中率
策略 1:禁用 cch(最有效)
如果你直连 Anthropic API(不经过网关),禁用 cch 可以立刻改善缓存命中率。这是所有优化中效果最显著的一步。
1 | { |
如果你通过 LLM 网关使用,更应该禁用——网关通常会自己实现缓存,cch 的每轮变化会直接破坏网关的缓存逻辑。
策略 2:保持 CLAUDE.md 稳定且精简
CLAUDE.md 在每次请求中都作为前缀发送。如果你频繁修改它,缓存就会失效。
做法:
- 把 CLAUDE.md 控制在 200 行以内
- 只包含每次会话都需要的指令
- 不要放频繁变化的内容
1 | # 好的 CLAUDE.md(精简、稳定) |
1 | # 不好的 CLAUDE.md(太长、变化频繁) |
策略 3:将专用指令移到 Skills 中
CLAUDE.md 在每个会话启动时全量加载,但 Skills 只在调用时才加载。
如果你的 CLAUDE.md 中有”PR 审查规范”、”数据库迁移流程”等只在特定任务时才需要的内容,把它们移到 .claude/skills/ 目录下。
好处:
- 减少启动时的 token 消耗
- 不相关的会话不会加载这些内容
- 缓存前缀更短、更稳定
策略 4:用 Auto Memory 替代重复指令
如果每次新会话你都要输入同样的项目背景信息,说明你需要让 Claude 自己记住。
Claude Code 的 auto memory 会在会话中自动记录有用的信息(构建命令、调试经验、项目模式),下次会话自动加载。前 200 行或 25KB 的 MEMORY.md 会在启动时加载。
策略 5:避免在会话中频繁切换模型
切换模型会改变 API 请求的模型标识,可能导致缓存前缀变化。如果需要对比不同模型的效果,尽量在新会话中测试,而不是在同一个会话中来回切换。
策略 6:使用环境变量固定模型版本
如果你通过 Bedrock、Vertex 等第三方部署,用环境变量固定模型版本可以避免模型别名解析变化导致的缓存失效:
1 | export ANTHROPIC_DEFAULT_SONNET_MODEL='claude-sonnet-4-6' |
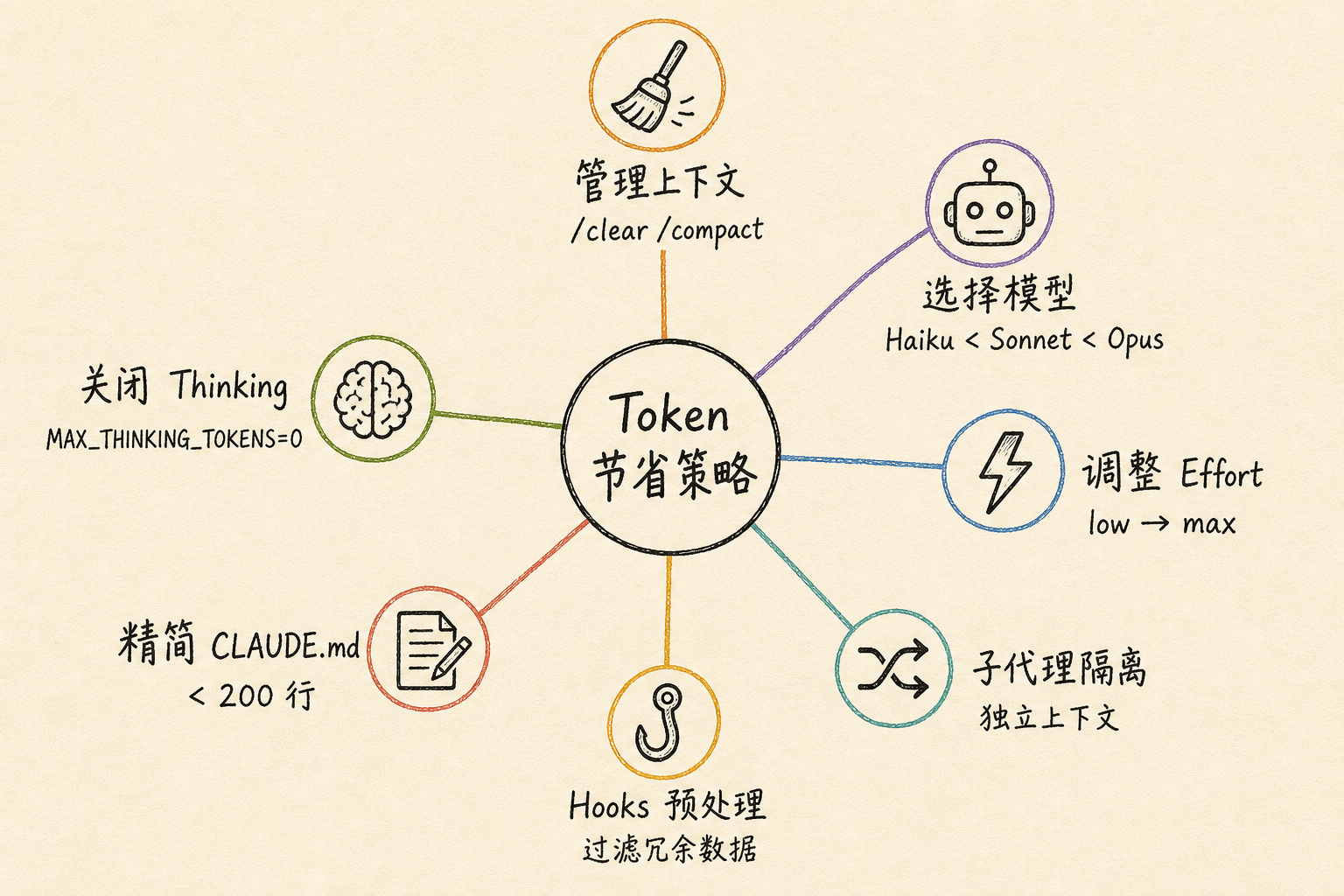
五、如何减少 Token 消耗
缓存命中率是一方面,减少总 token 消耗是另一方面。以下是实操技巧:
技巧 1:主动管理上下文
| 操作 | 时机 | 效果 |
|---|---|---|
/clear |
切换不相关任务时 | 清空上下文,重新开始 |
/compact |
上下文接近上限时 | 压缩历史,保留关键信息 |
/compact 专注保留代码改动 |
需要控制压缩内容时 | 指定压缩时保留什么 |
/rewind |
走错方向时 | 回退到之前的检查点 |
核心原则:上下文窗口是最重要的资源。每多一条无关信息,后续每轮对话都要为它付费。
技巧 2:选择合适的模型
| 模型 | 适合场景 | 成本 |
|---|---|---|
| Haiku | 简单任务、子代理 | 最低 |
| Sonnet | 日常编码(推荐默认) | 中等 |
| Opus | 复杂架构决策、深度推理 | 最高 |
用 /model 随时切换,或在配置中设置默认模型。对于子代理,可以用 model: haiku 来降低成本。
技巧 3:调整 Effort Level
Effort level 控制模型的推理深度,直接影响 token 消耗:
| 级别 | 适用场景 | token 消耗 |
|---|---|---|
low |
短小、低延迟任务 | 最低 |
medium |
成本敏感的常规任务 | 较低 |
high |
平衡型(推荐) | 中等 |
xhigh |
Opus 4.7 默认,最佳效果 | 较高 |
max |
最深推理,仅限当前会话 | 最高 |
用 /effort 交互式调整,或通过环境变量设置:
1 | |
技巧 4:用子代理隔离冗长操作
运行测试、读取大量文件、处理日志等操作会产生大量输出,如果都在主会话中进行,会迅速占满上下文。
1 | 用子代理调查认证系统的 |
子代理在独立的上下文窗口中运行,只返回摘要给主会话,不会污染你的主上下文。
技巧 5:用 Hooks 预处理数据
如果 Claude 需要读取一个 10,000 行的日志文件来找错误,可以用 hook 先 grep 出 ERROR 行,只返回匹配的几百行给 Claude。
1 | { |
技巧 6:精简 CLAUDE.md
| 应该包含 | 不应该包含 |
|---|---|
| Claude 猜不到的 bash 命令 | Claude 读代码就能知道的内容 |
| 与默认不同的代码规范 | 语言的标准约定 |
| 测试指令和首选测试运行器 | 详细的 API 文档(链接即可) |
| 仓库规范(分支命名、PR 约定) | 频繁变化的信息 |
| 项目特有的架构决策 | 长篇解释或教程 |
技巧 7:关闭不需要的 Extended Thinking
Extended thinking 默认开启,thinking tokens 按输出 token 计费,可能每次请求消耗数万个 token。
对于简单任务,可以关闭或降低:
1 | # 关闭 extended thinking |
也可以用 /config 在会话中切换。
六、通过 LLM 网关使用 Claude 的缓存优化
如果你通过 LiteLLM 等网关转发 Claude 请求,缓存面临双重挑战。
网关场景的缓存问题
Anthropic API 会自动剥离 x-anthropic-billing-header 中的 cch 字段再处理缓存,所以直连 API 时 cch 只影响前缀匹配。但网关通常不会剥离这个字段,而是基于完整请求体做缓存判断。此时 cch 每轮变化,网关的缓存永远不会命中。
此外,网关可能在请求中添加自己的 header 或 body 字段,进一步破坏前缀一致性。
完整配置示例
1 | # 基础网关配置 |
Claude Code 发送的 Header
Claude Code 在每次请求中会附带以下自定义 header,网关可以利用这些信息做请求聚合和成本归因:
| Header | 说明 |
|---|---|
X-Claude-Code-Session-Id |
当前会话的唯一标识 |
X-Claude-Code-Agent-Id |
发起请求的子代理标识(仅子代理请求时存在) |
X-Claude-Code-Parent-Agent-Id |
父代理标识(仅嵌套子代理时存在) |
如果你的网关需要按会话聚合成本,可以用 Session-Id 来关联同一会话的所有请求,而不需要解析请求体。
七、实际操作清单
立即可做的优化
- 禁用 cch:设置
CLAUDE_CODE_ATTRIBUTION_HEADER=0,这是提升缓存命中率最直接的一步 - 精简 CLAUDE.md:检查是否超过 200 行,删除不必要的内容
- 把专用指令移到 Skills:PR 审查、数据库迁移等只在特定任务需要的内容
- 养成 /clear 的习惯:切换任务时先清空上下文
- 用子代理处理冗长操作:测试、日志分析、代码探索
- 配置 status line 显示 token 使用量:实时监控上下文消耗
进阶优化
- 调整 effort level:简单任务用
low或medium - 关闭不需要的 extended thinking:
MAX_THINKING_TOKENS=0 - 用 hooks 预处理数据:过滤测试输出、日志等
- 固定模型版本:避免别名解析变化导致缓存失效
- 网关场景设置
CLAUDE_CODE_ATTRIBUTION_HEADER=0
监控与验证
- 用
/usage查看当前会话的 token 消耗 - 用
/context查看上下文占用分布 - 在 Claude Console 查看实际账单,对比缓存前后差异
总结
Prompt Caching 的核心逻辑是:让相同的内容反复发送时,只收 1/10 的费用。 Claude Code 已经自动帮你做了大部分缓存工作,但你仍然可以通过管理上下文、精简 CLAUDE.md、使用 Skills 和子代理来进一步优化。
记住一个原则:上下文窗口是最重要的资源,每多一条无关信息,后续每轮对话都要为它付费。